FACTS Grounding FACTS Grounding是一款由谷歌DeepMind研发的基准测试工具,专门用于评估大型语言模型在生成事实准确文本方面的能力。它通过设置包含多个领域的复杂任务,要求模型基于长文档生成响应,并采用两阶段评估流程验证事实准确性及避免“幻觉”。FACTS Grounding不仅支持信息检索与问答,还能应用于内容摘要生成、文档改写以及客户服务等领域,为模型提供全面而可靠的性能评估。 AI项目与工具 2025年06月12日 38 点赞 0 评论 701 浏览
FlagEval FlagEval作为一个专业的语言模型评估平台,为用户提供了一个可靠、标准化的评测环境。通过这个平台,研究人员和开发者可以全面了解模型的性能,推动语言模型技术的不断进步和创新。 创作工具 2026年07月28日 0 点赞 0 评论 705 浏览
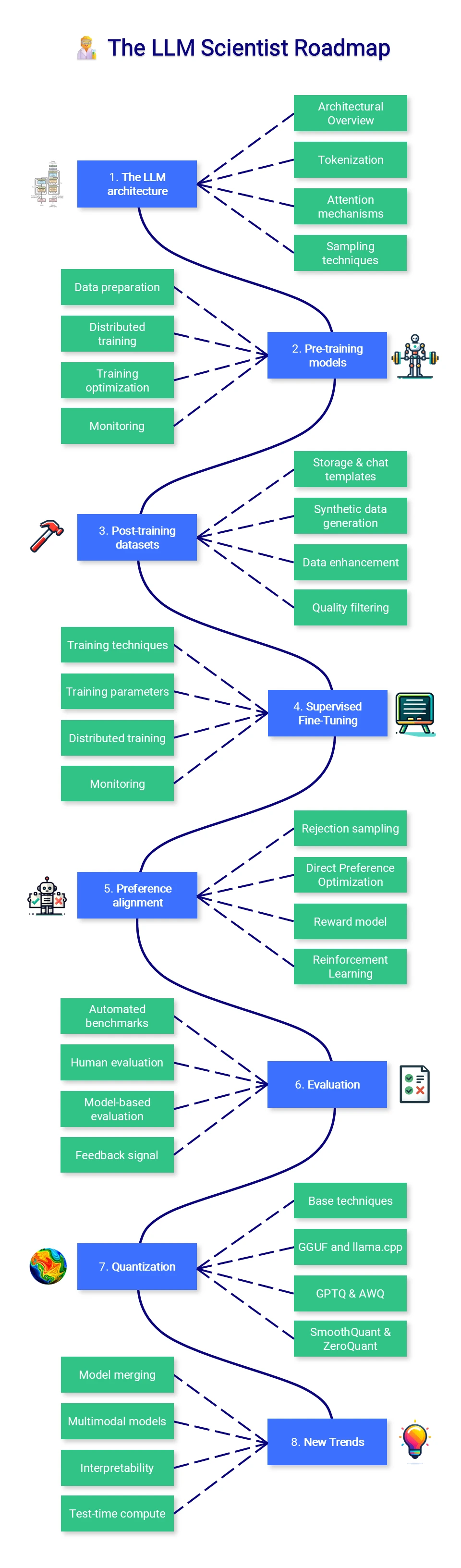
LLM Course 一个关于LLMs课程的集合,包含学习路线图和Colab笔记本,帮助用户从基础到高级逐步掌握LLMs的知识和应用。 Ai学习资源 2025年06月05日 85 点赞 0 评论 706 浏览
Kimi学术搜索 Kimi学术搜索是一款基于人工智能技术的学术研究辅助工具,通过深度推理、信息整合及实时交互等功能,帮助用户高效地获取学术资源。其主要特点包括多语言支持、自我评估改进机制以及对复杂任务的精准响应能力,广泛应用于学术研究、市场分析、学习辅导和技术支持等领域。 AI项目与工具 2025年06月12日 37 点赞 0 评论 707 浏览
VSI VSI-Bench是一种用于评估多模态大型语言模型(MLLMs)视觉空间智能的基准测试工具,包含超过5000个问题-答案对,覆盖多种真实室内场景视频。其任务类型包括配置型任务、测量估计和时空任务,可全面评估模型的空间认知、理解和记忆能力,并提供标准化的测试集用于模型性能对比。 --- AI项目与工具 2025年06月12日 10 点赞 0 评论 719 浏览
moonshot moonshot-v1-vision-preview 是一款由月之暗面开发的多模态图像理解模型,具备精准的图像识别、OCR 文字识别和数据解析能力。支持 API 集成,适用于内容审核、文档处理、医学分析、智能交互等多个领域。模型可识别复杂图像细节、分析图表数据,并从美学角度进行图像评价,适合需要高效图像处理和智能交互的应用场景。 AI项目与工具 2025年06月12日 52 点赞 0 评论 725 浏览
AlphaEvolve AlphaEvolve是谷歌DeepMind开发的通用科学代理,结合大型语言模型与进化算法,用于设计和优化复杂算法。它在数据中心调度、硬件设计、AI训练和数学问题解决等领域取得显著成果,如优化矩阵乘法、提升系统效率等。系统采用自动化评估机制,支持跨领域应用,具备高效计算和持续优化能力。 AI项目与工具 2025年06月11日 98 点赞 0 评论 726 浏览
MMBench MMBench-Video是一个由多家高校和机构联合开发的长视频多题问答基准测试平台,旨在全面评估大型视觉语言模型(LVLMs)在视频理解方面的能力。平台包含约600个YouTube视频片段,覆盖16个类别,并配备高质量的人工标注问答对。通过自动化评估机制,MMBench-Video能够有效提升评估的精度和效率,为模型优化和学术研究提供重要支持。 AI项目与工具 2025年06月12日 52 点赞 0 评论 730 浏览
Sitespeak.ai SiteSpeakAI可以通过使用您网站的内容、文档、知识自定义 AI 聊天机器人,训练一个可以回答你产品和服务的24/7 全天候实时提供服务的聊天机器人。 电商运营 2025年06月05日 11 点赞 0 评论 734 浏览
Promptim Promptim是一款实验性的AI提示优化工具,旨在通过自动化优化循环提升AI系统在特定任务中的表现。其主要功能包括自动化提示优化、自定义评估器集成、人工反馈循环及多轮优化。Promptim支持文本生成、对话系统、机器翻译、情感分析和教育等多个应用场景,通过数据驱动的优化方法和元提示策略,帮助用户快速生成更高效的提示,显著提升AI系统的性能。 AI项目与工具 2025年06月12日 19 点赞 0 评论 734 浏览