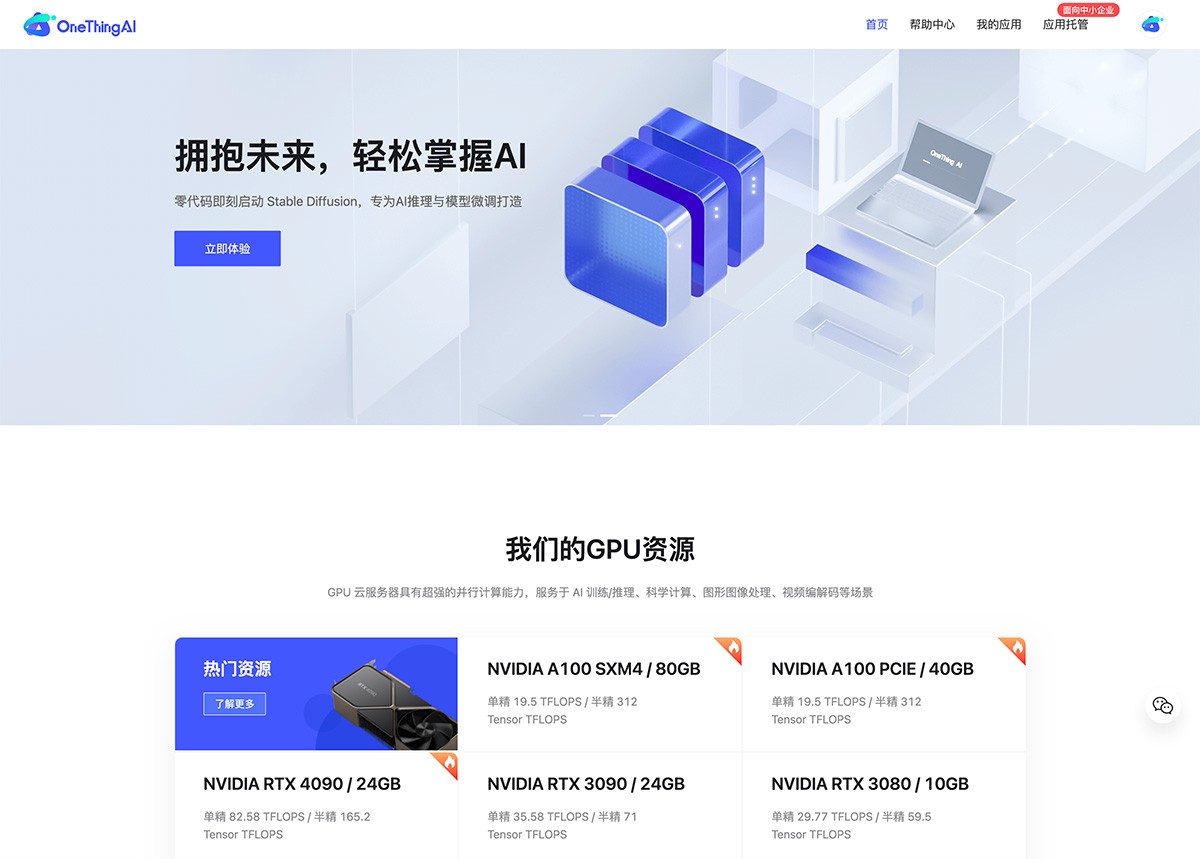
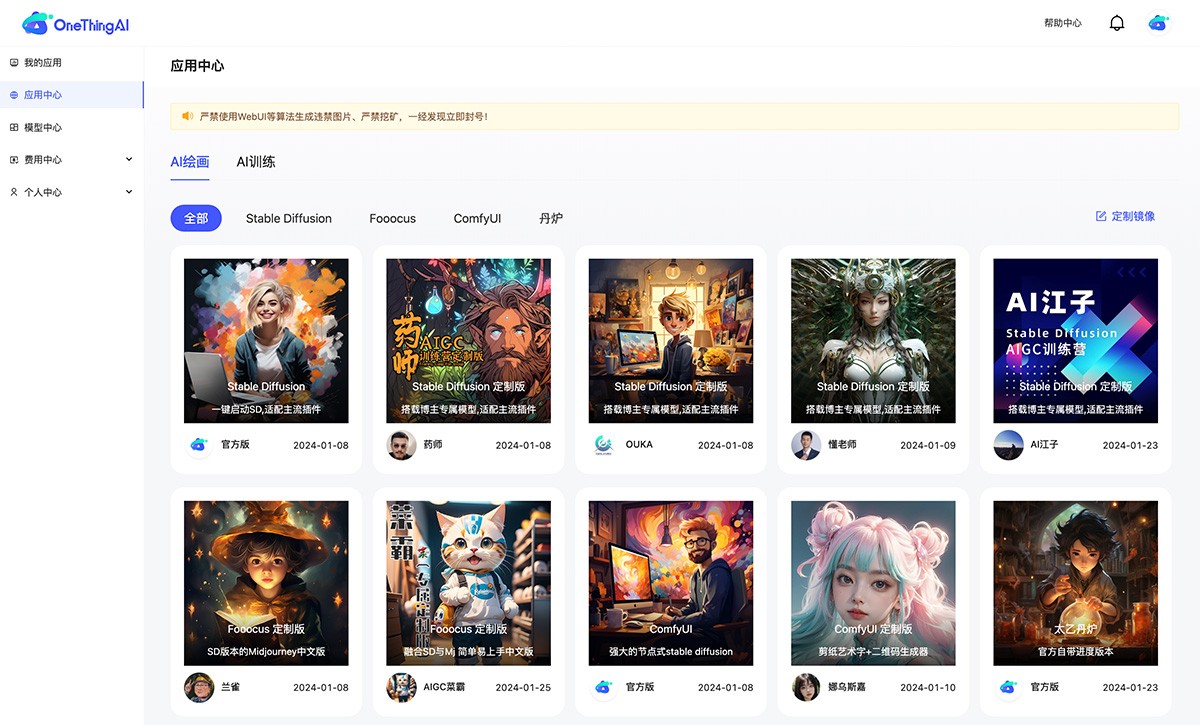
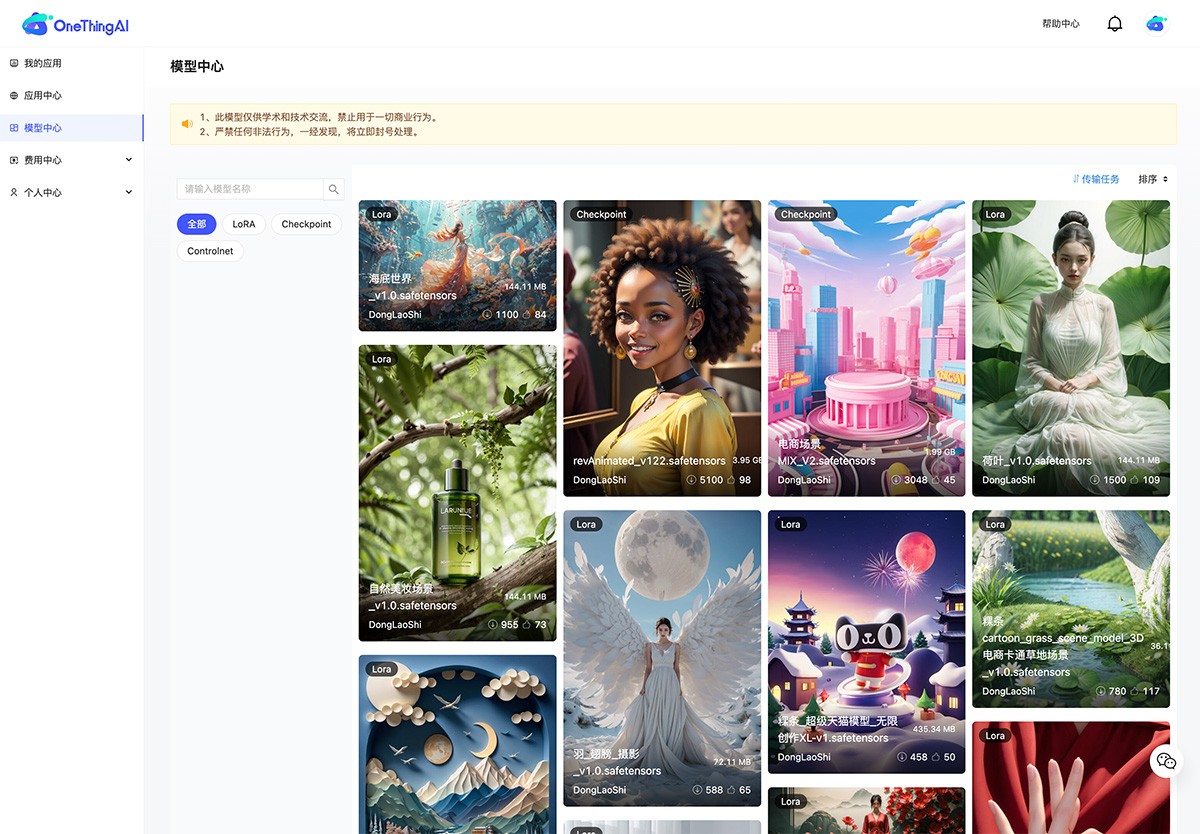
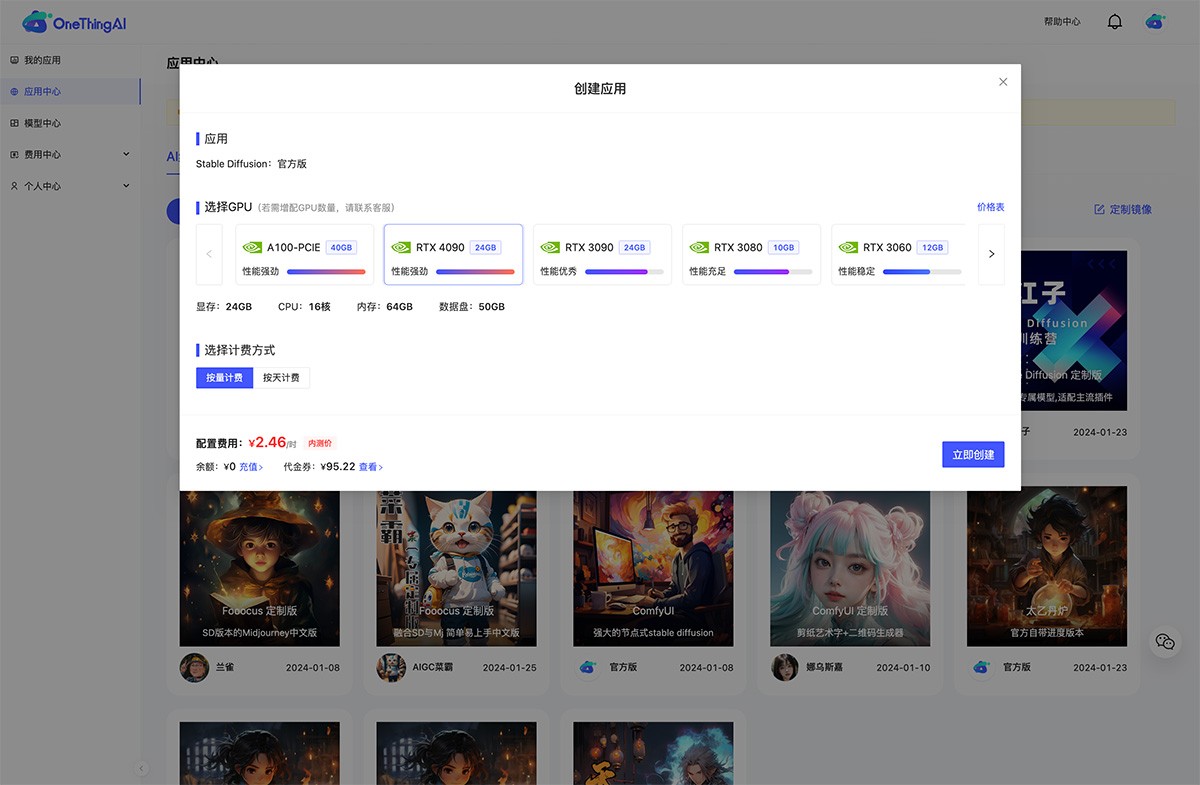
计算

每天一节免费AIGC视频课
AIGC教程涵盖了GPT进阶教程、AI绘画教程(例如Midjourney、Stable Diffusion)、电商设计等多种AI设计培训课。


MotionCtrl
强大的视频生成工具,它通过精确控制视频中的相机和物体运动,为视频制作带来了新的可能性。无论是简单的运动场景还是复杂的交互动作,MotionCtrl都能够提供令人满意的解决方案。


欣智TaxGPTs大模型
欣智TaxGPTs大模型是由方欣科技推出的一款专注于财税领域的大模型,它通过大量的财税数据预训练和自我学习,具备丰富的财税服务能力。