DICE DICE-Talk是由复旦大学与腾讯优图实验室联合开发的动态肖像生成框架,能够根据音频和参考图像生成具有情感表达的高质量视频。其核心在于情感与身份的解耦建模,结合情感关联增强和判别机制,确保生成内容的情感一致性与视觉质量。该工具支持多模态输入,具备良好的泛化能力和用户自定义功能,适用于数字人、影视制作、VR/AR、教育及心理健康等多个领域。 AI项目与工具 2025年06月11日 87 点赞 0 评论 713 浏览
千颜 千颜是一款依托AI技术的照片和视频编辑工具,提供多样化的穿搭风格与视频模板,支持用户快速生成写真照片和视频。其主要功能包括AI一键换装、海量风格模板、视频换装以及图片动态化处理,满足个性化创意需求。应用场景广泛,包括个人娱乐、社交媒体内容创作、教育学习等。 AI项目与工具 2025年06月12日 60 点赞 0 评论 713 浏览
LanDiff LanDiff是一种结合自回归语言模型和扩散模型的文本到视频生成框架,采用粗到细的生成策略,有效提升语义理解与视觉质量。其核心功能包括高效语义压缩、高质量视频生成、语义一致性保障及灵活控制能力。支持长视频生成,降低计算成本,适用于视频制作、VR/AR、教育及社交媒体等多个领域。 AI项目与工具 2025年06月12日 92 点赞 0 评论 712 浏览
97文案 97文案是一家电商Ai智能文案平台,能够帮助到电商卖家轻松写出专业的电商文案,可帮您用 Ai生成广告文案、Ai生成短视频脚本、Ai生成商品卖点等。 剧本文案 2025年06月05日 14 点赞 0 评论 712 浏览
UniFab 一款功能强大的视频增强工具,UniFab具有AI驱动的升频、降噪、SDR 到 HDR 转换以及其他多种功能,提升视频质量,满足专业人士和爱好者的需求。 视频剪辑 2025年06月05日 21 点赞 0 评论 712 浏览
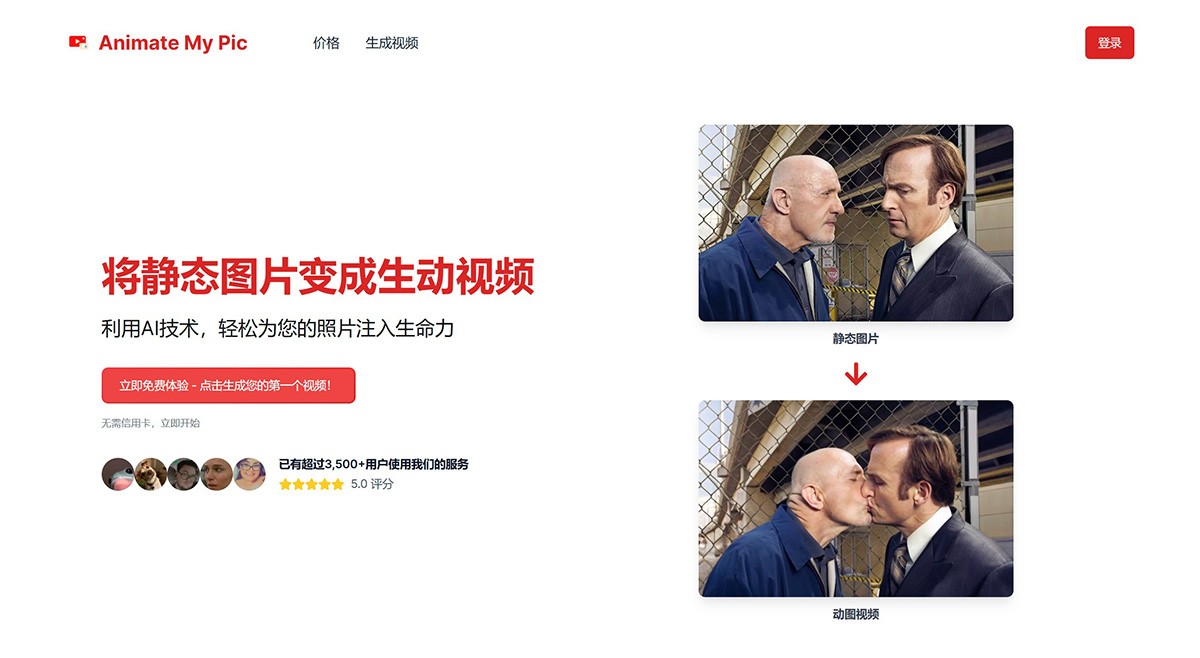
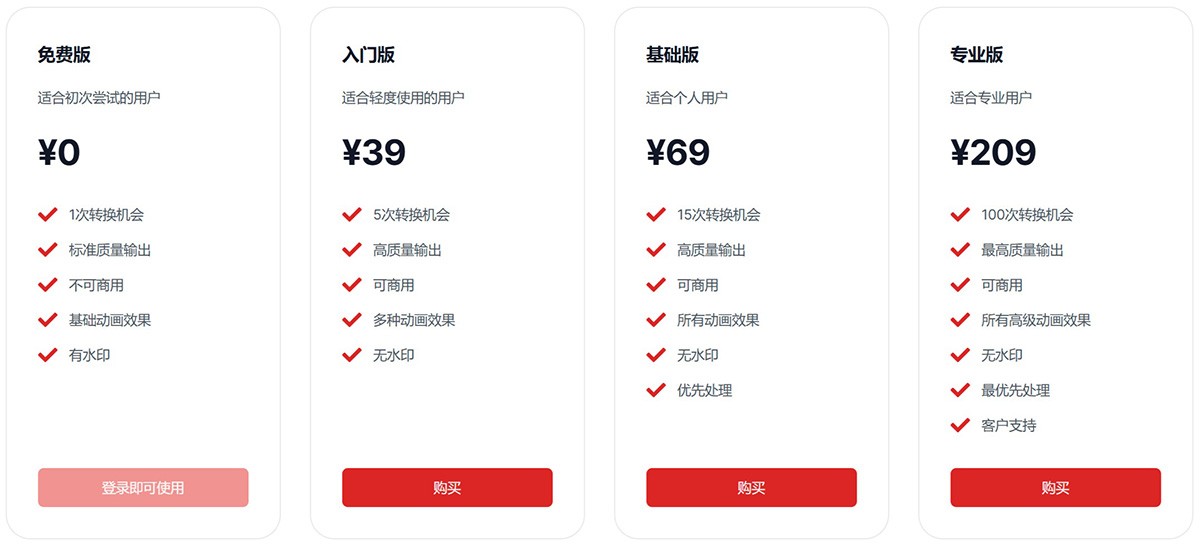
AnimateMyPic 一个能将静态照片或老照片转化为视频的工具。通过AnmianteMyPic这款基于人工智能的工具,您可以轻松地为您的图片增添生动的动画效果,让您的图片焕发全新的魅力。 Ai视频生成 2025年06月05日 12 点赞 0 评论 712 浏览