Metaview Metaview是一款利用人工智能技术的面试摘要工具,可自动记录和整理面试内容,生成结构化摘要,帮助招聘团队高效处理候选人信息。其核心功能包括关键信息提取、模板定制、数据安全保护以及与主流招聘系统的无缝集成,广泛应用于大规模招聘、远程面试和技术岗位筛选等场景。 AI项目与工具 2025年06月12日 46 点赞 0 评论 891 浏览
Genmo Genmo是一个创造和分享交互式、沉浸式生成艺术的平台。通过创建视频、3D场景、动画、矢量设计资产等,超越Genmo上的2D图像。 Ai视频生成 2026年07月28日 0 点赞 0 评论 890 浏览
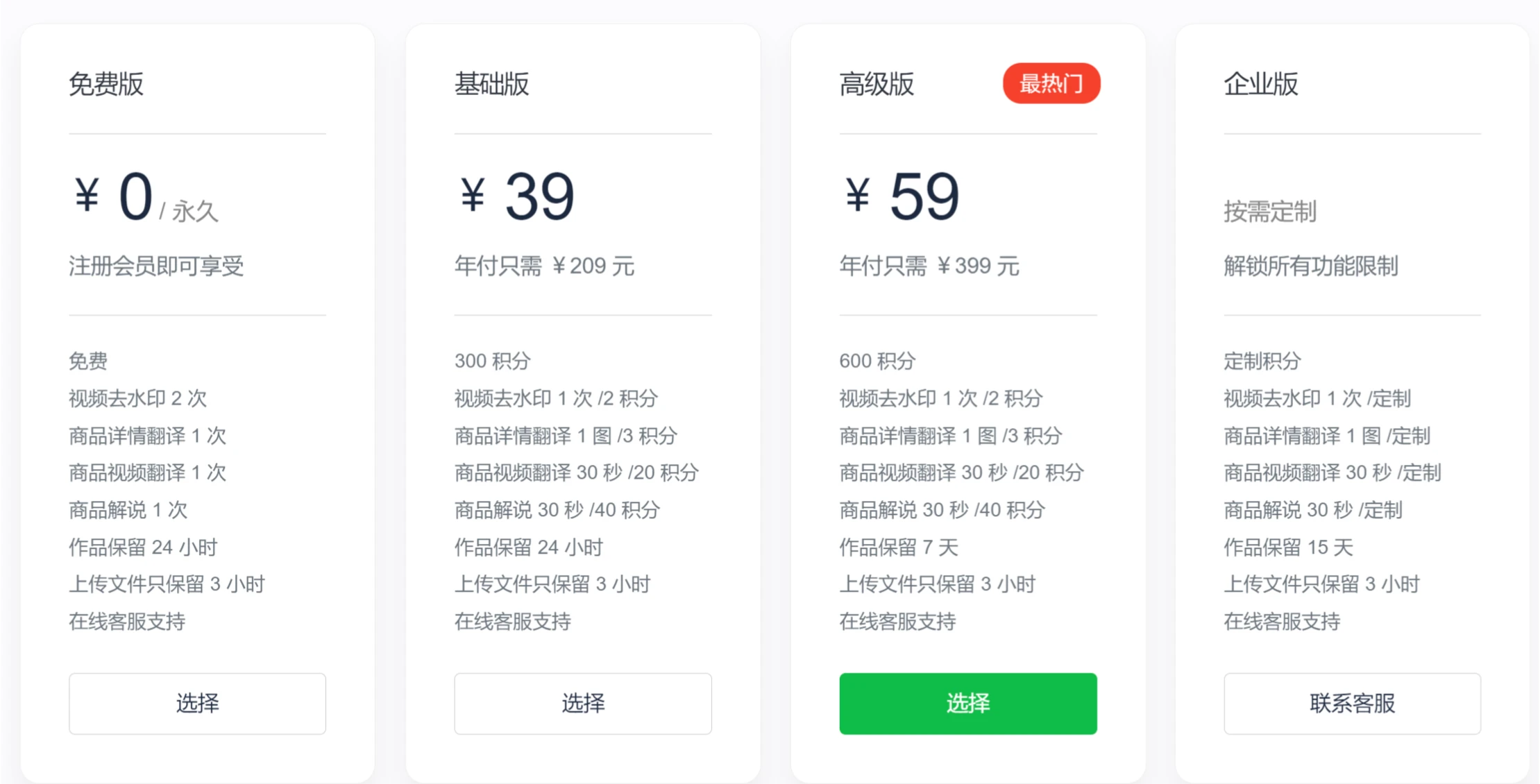
光映AI视频创作平台 一款 AI驱动的视频创作平台,可快速将文字、图片等内容转化为 TikTok、Instagram 、YouTube 视频与虚拟形象视频,无需视频编辑技能。 Ai视频生成 2025年06月05日 29 点赞 0 评论 890 浏览
Animon Animon 是日本 Animon Dream Factory 推出的全球首个专注于动漫制作的 AI 视频生成平台。它结合日本传统动漫美学与尖端 AI 技术,用户只需上传一张插画或 CG 图片并输入动作描述,即可在 3 分钟内生成 5 秒的动画视频。平台具备专业二次元质感、快速生成、无限生成与低成本等特点,适用于二次元内容创作、创意尝试、前期制作、动画资源生成和动画教学等场景。 AI项目与工具 2025年06月11日 41 点赞 0 评论 889 浏览