视频


麦壳下载VGO.PUB
一款在线视频下载工具,只需点击一下,可以在几秒钟内从其他视频网站保存高质量视频。速度比任何免费的在线视频下载器更快,并提供一键去除视频水印的功能。

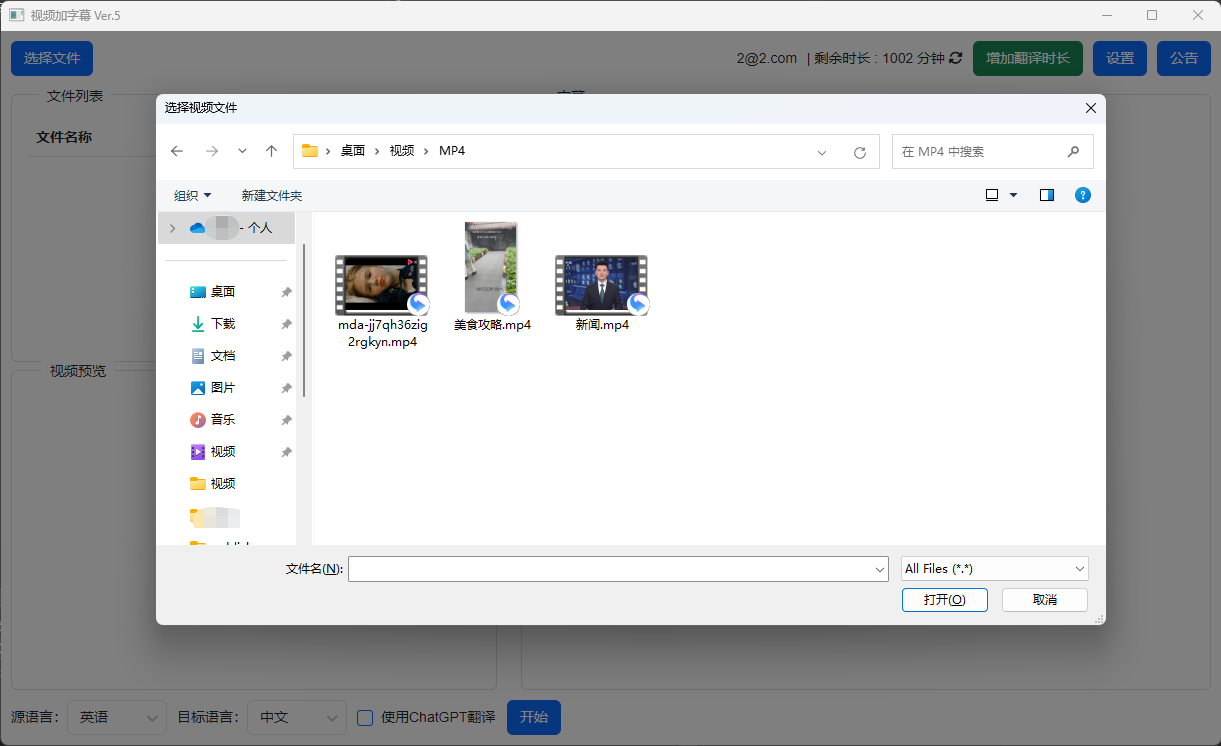

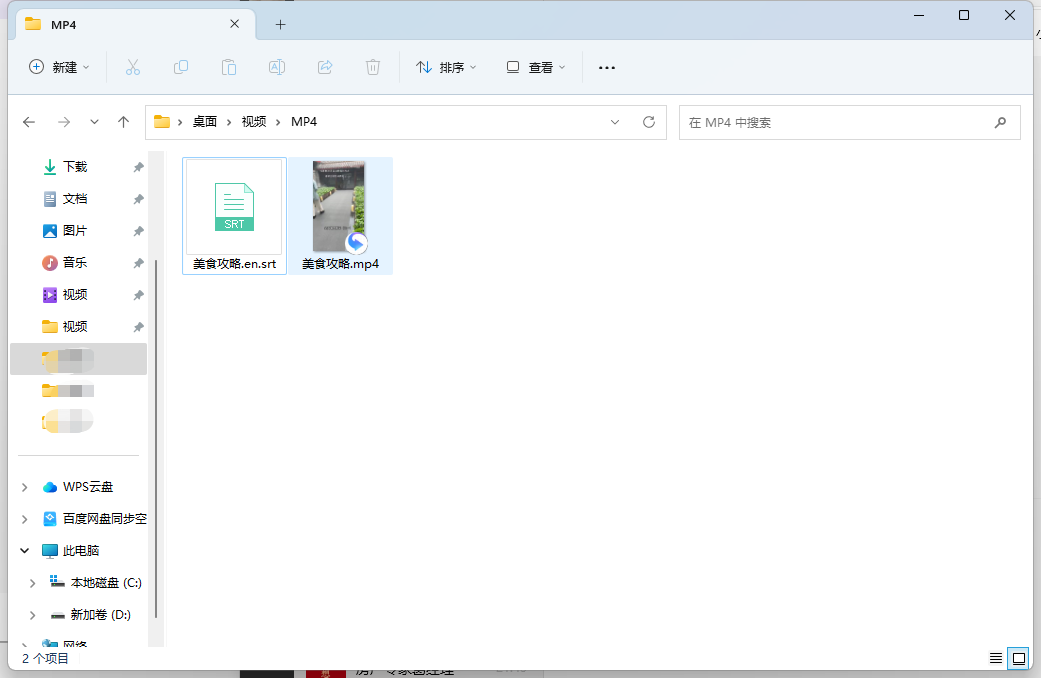
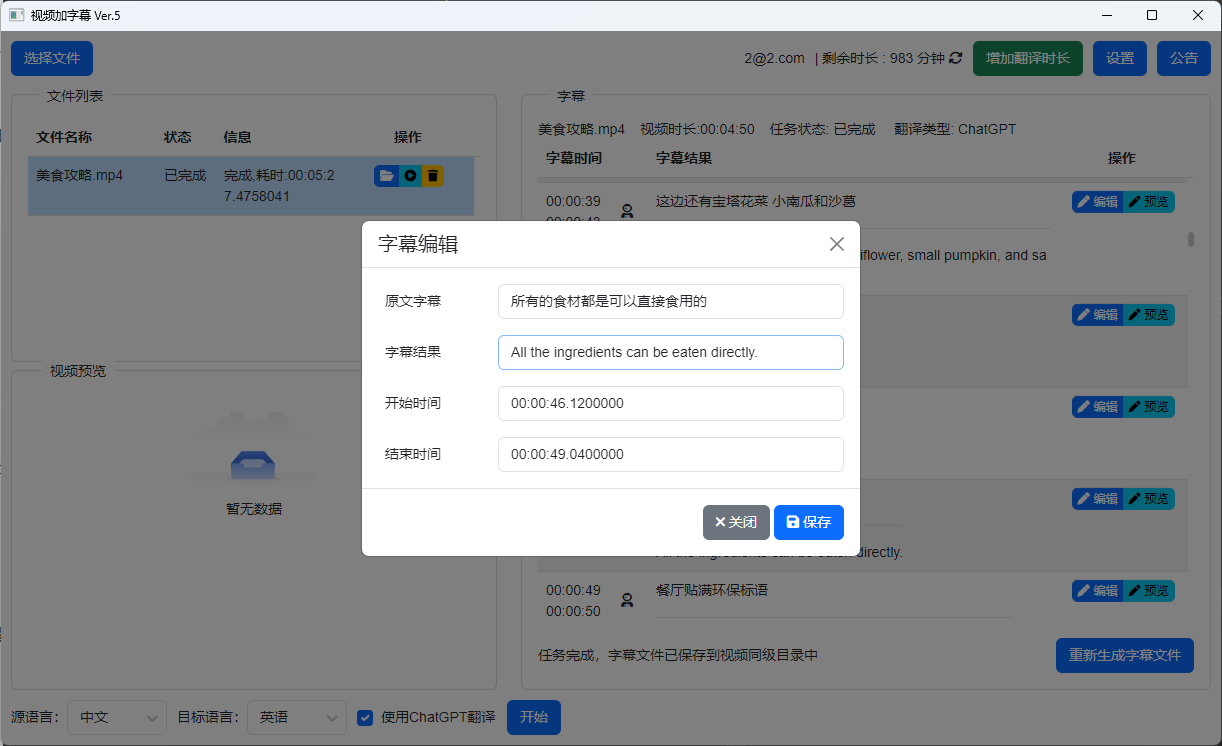





KuaiFormer
KuaiFormer是一款基于Transformer架构的检索框架,专为大规模内容推荐系统设计。它通过重新定义检索流程,将传统分数估计任务转换为“下一个动作预测”,从而实现高效的多兴趣提取和实时兴趣捕捉。KuaiFormer具备多兴趣查询Token、自适应序列压缩、稳定训练等核心技术,已在快手App的短视频推荐系统中广泛应用,显著提升了用户体验和平台效率。
---

TikTok Voice
TikTok Voice 是一款基于人工智能的文字转语音工具,提供多种声音选项,支持多种语言和口音。它能将文本转换成清晰自然的语音,适用于视频编辑、文本朗读、有声电子书制作等多个场景。该工具界面简洁,操作便捷,且完全免费,适合全球用户使用。
