LatentSync LatentSync是由字节跳动与北京交通大学联合研发的端到端唇形同步框架,基于音频条件的潜在扩散模型,无需中间3D或2D表示,可生成高分辨率、动态逼真的唇同步视频。其核心技术包括Temporal Representation Alignment (TREPA)方法,提升视频时间一致性,并结合SyncNet监督机制确保唇部动作准确。适用于影视制作、教育、广告、远程会议及游戏开发等多个领域。 AI项目与工具 2025年06月12日 95 点赞 0 评论 870 浏览
FramePack FramePack 是斯坦福大学推出的开源 AI 视频生成模型,通过帧上下文打包和抗漂移采样技术,实现高效、稳定的视频生成。其仅需 6GB 显存即可运行,支持实时高清视频生成,具备灵活的调度策略,适用于多种应用场景,如短视频制作、游戏开发、教育与广告等,显著降低了视频生成的硬件门槛。 AI项目与工具 2025年06月11日 23 点赞 0 评论 870 浏览
StoryDiffusion StoryDiffusion 是一种基于 AI 的图像和视频生成框架,通过 Consistent Self-Attention 和 Semantic Motion Predictor 技术,实现从文本到连贯图像和视频的转化,支持用户高效生成高质量视觉内容,广泛应用于动漫、教育、广告及影视等领域。 AI项目与工具 2025年06月12日 48 点赞 0 评论 867 浏览
AniPortrait AniPortrait是一款由腾讯开源的AI视频生成框架,通过音频和一张参考肖像图片生成高质量的动画。该框架包含两个核心模块:Audio2Lmk模块将音频转换为2D面部标记点,而Lmk2Video模块则基于这些标记点生成连贯且逼真的视频动画。AniPortrait以其高质量的视觉效果、时间一致性和灵活的编辑能力著称,能够精确捕捉面部表情和嘴唇动作。 AI项目与工具 2025年06月12日 68 点赞 0 评论 865 浏览
TransPixar TransPixar是由多所高校及研究机构联合开发的开源文本到视频生成工具,基于扩散变换器(DiT)架构,支持生成包含透明度信息的RGBA视频。该技术通过alpha通道生成、LoRA微调和注意力机制优化,实现高质量、多样化的视频内容生成。适用于影视特效、广告制作、教育演示及虚拟现实等多个领域,为视觉内容创作提供高效解决方案。 AI项目与工具 2025年06月12日 17 点赞 0 评论 861 浏览
sCM sCM是一种由OpenAI开发的基于扩散模型的连续时间一致性模型,通过简化理论框架与优化采样流程,实现了图像生成速度的大幅提升。该模型仅需两步采样即可生成高质量图像,且速度比传统扩散模型快50倍。得益于连续时间框架和多项技术改进,sCM不仅提高了训练稳定性,还提升了生成质量。其应用场景广泛,包括视频生成、3D建模、音频处理及跨媒介内容创作,适用于艺术设计、游戏开发、影视制作等多个行业。 AI项目与工具 2025年06月12日 50 点赞 0 评论 860 浏览
Spikes Studio Spikes Studio是一个将长视频转化为YouTube、TikTok和Reels病毒视频的工具。它具有强大的AI编辑器,自动添加字幕等功能。 视频剪辑 2025年06月05日 51 点赞 0 评论 860 浏览
Pollo AI Pollo AI是一款由HIX.AI推出的AI视频创作平台,支持文本、图像及视频风格转换等多种功能,能将文字或图片快速生成高质量视频。平台具备角色一致性保障、多风格转换、高清输出等特性,适用于短视频制作、品牌推广、教学视频等领域,为用户提供高效的AI视频生成体验。 AI项目与工具 2025年06月11日 71 点赞 0 评论 860 浏览
Vid2World Vid2World是由清华大学和重庆大学联合开发的创新框架,能够将全序列、非因果的被动视频扩散模型(VDM)转换为自回归、交互式、动作条件化的世界模型。该模型基于视频扩散因果化和因果动作引导两大核心技术,解决了传统VDM在因果生成和动作条件化方面的不足。Vid2World支持高保真视频生成、动作条件化、自回归生成和因果推理,适用于机器人操作、游戏模拟等复杂环境,具有广泛的应用前景。 AI项目与工具 2025年06月11日 33 点赞 0 评论 858 浏览
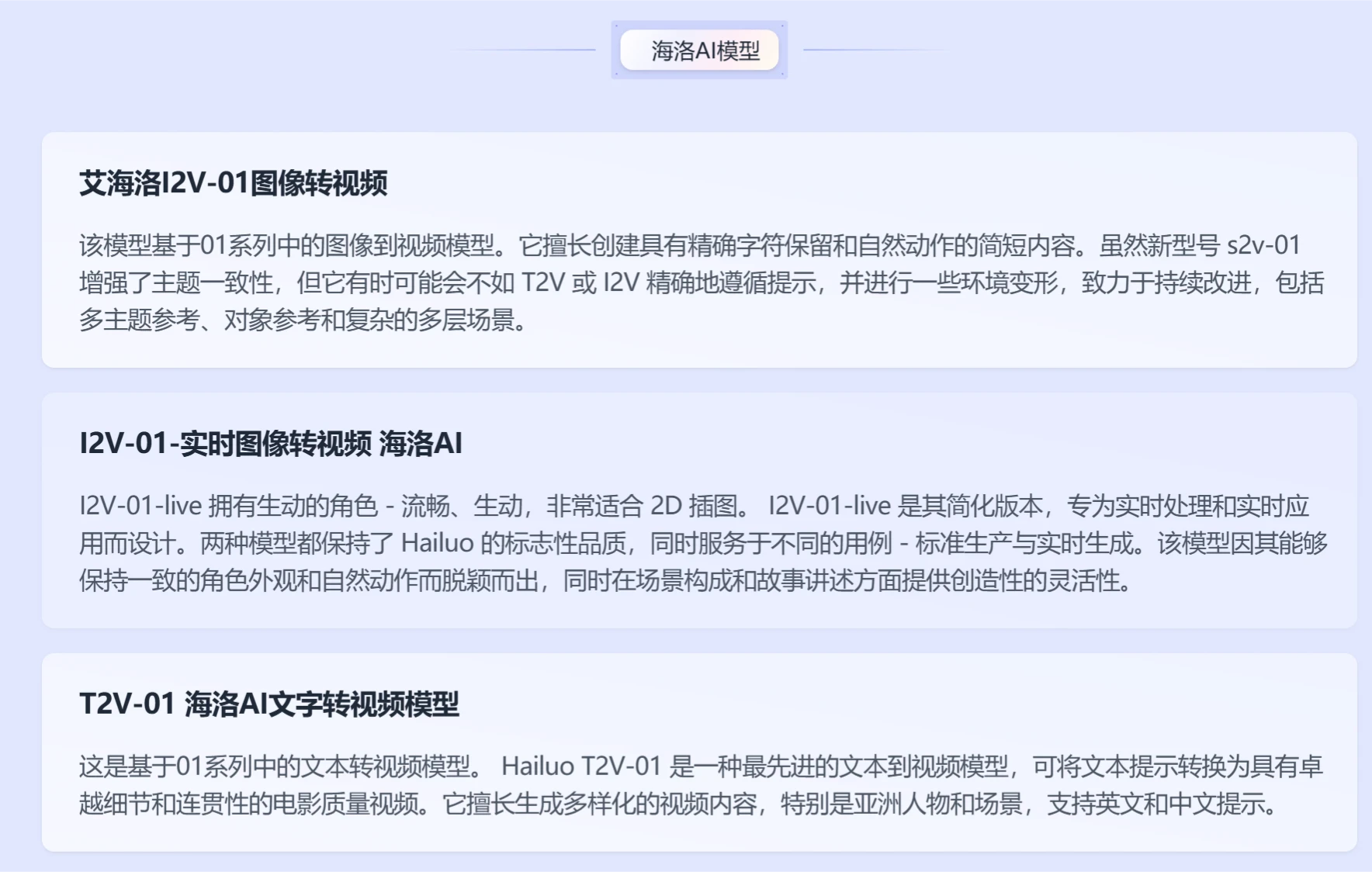
S2V.Ai 海螺AI推出的一款基于S2V-01模型的AI视频生成工具,只需输入一张图片即可生成具有高保真度、灵活性和可组合性的视频。 Ai视频生成 2025年06月05日 45 点赞 0 评论 858 浏览