灵伴科技Rokid 也和称Rokid,2014年成立,总部在杭州,创始人是前阿里巴巴M工作室负责人祝铭明,是一家专注于AI与AR技术的杭州高科技公司。 Ai科技公司 2025年06月05日 28 点赞 0 评论 740 浏览
Titans Titans是谷歌推出的新型神经网络架构,突破了传统Transformer在处理长序列数据时的限制。其核心是神经长期记忆模块,可模拟人脑记忆机制,提升对关键信息的存储与提取能力。Titans支持多种任务,包括语言建模、常识推理和时间序列预测,尤其在处理超长上下文时表现优异。该架构具备并行计算能力,提高了训练效率,适用于文本生成、生物信息学、视频音乐处理等多个领域。 AI项目与工具 2025年06月12日 27 点赞 0 评论 740 浏览
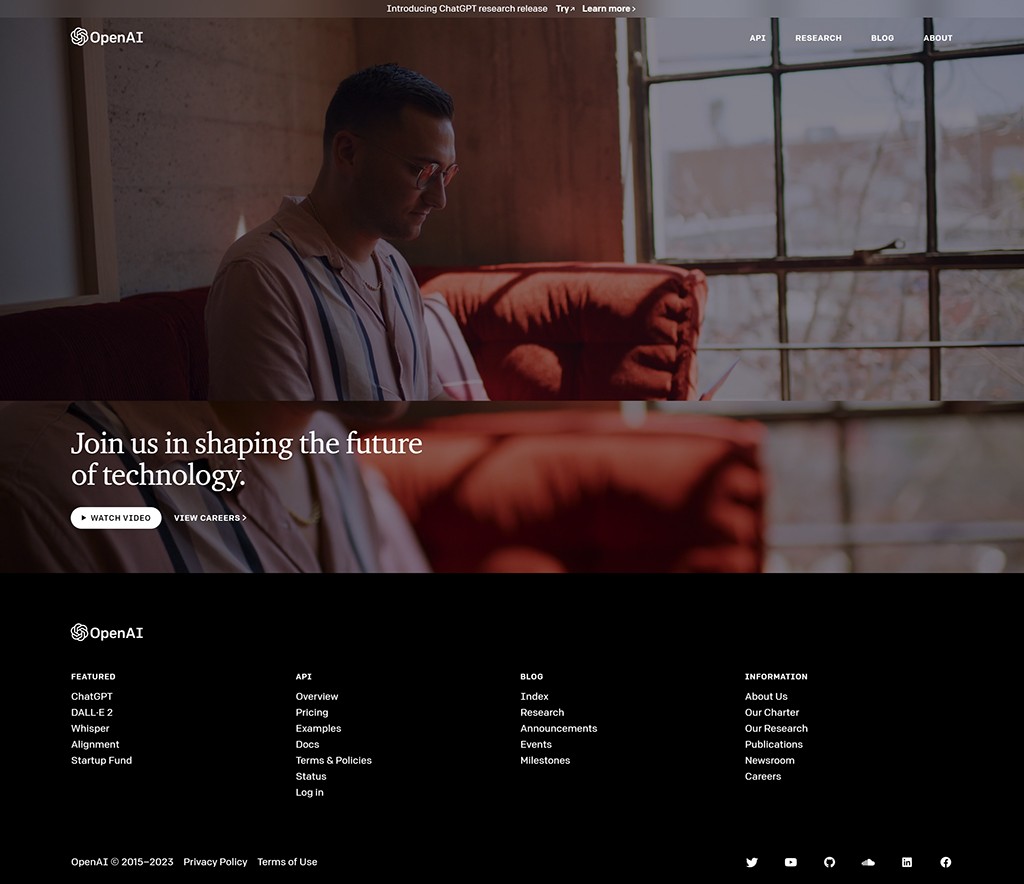
Openai ChatGPT,美国OpenAI研发的聊天机器人程序 ,它能够通过学习和理解人类的语言来进行对话,还能根据聊天的上下文进行互动,真正像人类一样来聊天交流,甚至能完成撰写邮件、视频脚本、文案、翻译、代码,写论文等任务。 Ai平台模型 2025年06月05日 81 点赞 0 评论 741 浏览
Grok Grok-1是由xAI公司开发的大型语言模型,具备3140亿参数,是目前参数量最大的开源大语言模型之一。该模型基于Transformer架构,专用于自然语言处理任务,如问答、信息检索、创意写作和编码辅助等。尽管在信息处理方面表现出色,但需要人工审核以确保准确性。此外,Grok-1还提供了8bit量化版本,以降低存储和计算需求。 AI项目与工具 2024年01月01日 10 点赞 0 评论 742 浏览
ExperAI ExperAI是一款基于AI聊天机器人的创新型平台,支持文本和语音交互,可上传文档和自定义知识库以提升对话个性化水平。其功能包括创建数字个性、知识分享、客户服务、个性化推荐及社交媒体集成等,广泛应用于客户服务、教育、健康咨询、个人助理和市场调研等领域,旨在通过自然语言处理技术,为用户提供深入且高效的对话体验。 AI项目与工具 2025年06月12日 82 点赞 0 评论 742 浏览
MiLoRA MiLoRA是一种参数高效的大型语言模型微调方法,通过奇异值分解将权重矩阵分为主要和次要两部分,专注于次要部分的优化以降低计算成本,同时保持模型的高精度和高效性。它在自然语言处理任务中表现出色,适用于文本分类、情感分析、问答系统等多个领域,并在多租户环境和实时内容生成中展现出显著优势。 --- AI项目与工具 2025年06月12日 47 点赞 0 评论 742 浏览
Chat2SVG Chat2SVG 是一种基于大语言模型和图像扩散模型的文本到 SVG 生成工具,能够自动创建高质量矢量图形。通过多阶段处理流程,包括模板生成、细节增强和形状优化,确保图形在视觉质量和语义对齐方面达到较高标准。支持自然语言指令编辑,适用于设计原型、图标创作、教育演示及艺术创作等多种场景。 AI项目与工具 2025年06月12日 74 点赞 0 评论 745 浏览
Melty Melty是一款开源的AI编程助手,旨在提升开发者的编码效率和代码质量。它能够实时理解开发者从终端到GitHub的编码内容,提供智能协作和代码生成。Melty具备学习能力,能够适应并模仿开发者的编程风格,与编译器、调试器等开发工具无缝集成。此外,它还支持代码重构、Web应用开发以及大型代码库的浏览等高级功能。通过自然语言处理、机器学习、代码生成和上下文感知等技术,Melty不仅提高了代码的质量和稳 AI项目与工具 2025年06月12日 76 点赞 0 评论 747 浏览
Sa2VA Sa2VA是由字节跳动联合多所高校开发的多模态大语言模型,结合SAM2与LLaVA技术,实现对图像和视频的密集、细粒度理解。它支持指代分割、视觉对话、视觉提示理解等多种任务,具备零样本推理能力和复杂场景下的高精度分割效果。适用于视频编辑、智能监控、机器人交互、内容创作及自动驾驶等多个领域。 AI项目与工具 2025年06月12日 66 点赞 0 评论 747 浏览