模型


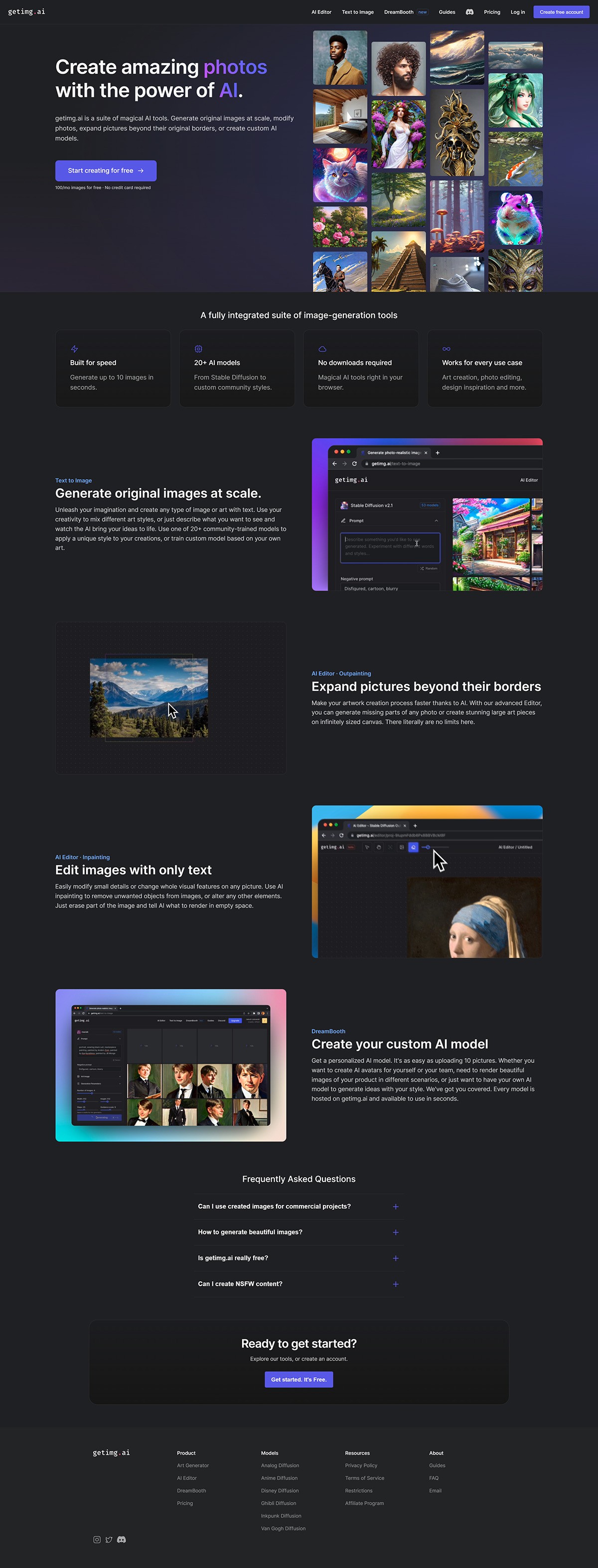






KTransformers
KTransformers是一款由清华大学KVCache.AI团队与趋境科技联合开发的开源工具,用于提升大语言模型的推理性能并降低硬件门槛。它支持在24GB显卡上运行671B参数模型,利用MoE架构和异构计算策略实现高效推理,预处理速度达286 tokens/s,推理速度达14 tokens/s。项目提供灵活的模板框架,兼容多种模型,并通过量化和优化技术减少存储需求,适合个人、企业及研究场景使用。

