AbletonMCP AbletonMCP 是一个开源工具,通过模型上下文协议(MCP)将 Ableton Live 与 Claude AI 连接,实现音乐制作过程中的 AI 辅助。支持双向通信,允许用户通过 AI 创建和编辑 MIDI 与音频轨道、选择乐器和效果、控制播放等。技术上采用 JSON 协议和套接字通信,适用于音乐创作、实时制作、教学及音频后期处理等多种场景。 AI项目与工具 2025年06月12日 99 点赞 0 评论 572 浏览
百聆 百聆是一款开源语音对话系统,融合语音识别、语音活动检测、大语言模型和语音合成技术,实现自然流畅的语音交互。支持低延迟运行,无需GPU,适用于边缘设备。具备记忆、工具调用和任务管理等功能,适用于智能家居、个人助理、车载系统等多种场景,提供高效的语音交互解决方案。 AI项目与工具 2025年06月12日 90 点赞 0 评论 572 浏览
HealthBench HealthBench是OpenAI推出的开源医疗评估工具,用于衡量大型语言模型在医疗保健领域的表现和安全性。它包含5000个由医生设计的多轮对话,涵盖多种健康场景,并通过多维度评分标准评估模型的准确性、沟通质量等。支持按主题和行为维度进行细分分析,帮助开发者识别模型优势与不足,指导优化方向。适用于模型性能评估、安全测试及医疗AI工具选择。 AI项目与工具 2025年06月11日 79 点赞 0 评论 572 浏览
SmolDocling SmolDocling-256M-preview 是一款轻量级多模态文档处理模型,能将图像文档高效转换为结构化文本,支持文本、公式、图表等多种元素识别。模型参数量仅256M,推理速度快,适合学术与技术文档处理。具备OCR、布局识别、格式导出等功能,并兼容Docling,适用于文档数字化、科学研究及移动环境应用。 AI项目与工具 2025年03月22日 98 点赞 0 评论 572 浏览
Granite 3.1 Granite 3.1是IBM推出的一款先进语言模型,具备强大的上下文处理能力和多语言支持功能。其核心特性包括扩展至128K tokens的上下文窗口、全新嵌入模型以及功能调用幻觉检测能力。该模型适用于客户服务自动化、内容创作、企业搜索、语言翻译及合规性检查等多种应用场景。 AI项目与工具 2025年06月12日 46 点赞 0 评论 571 浏览
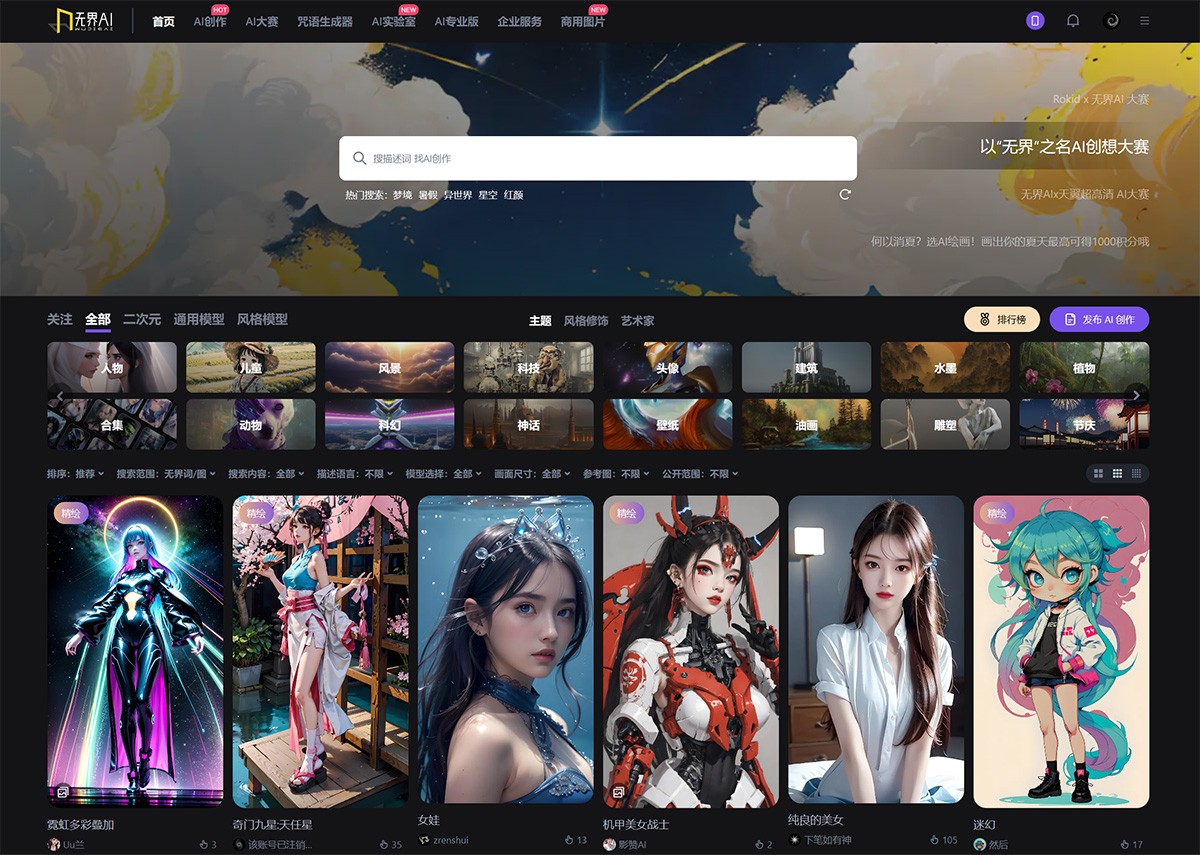
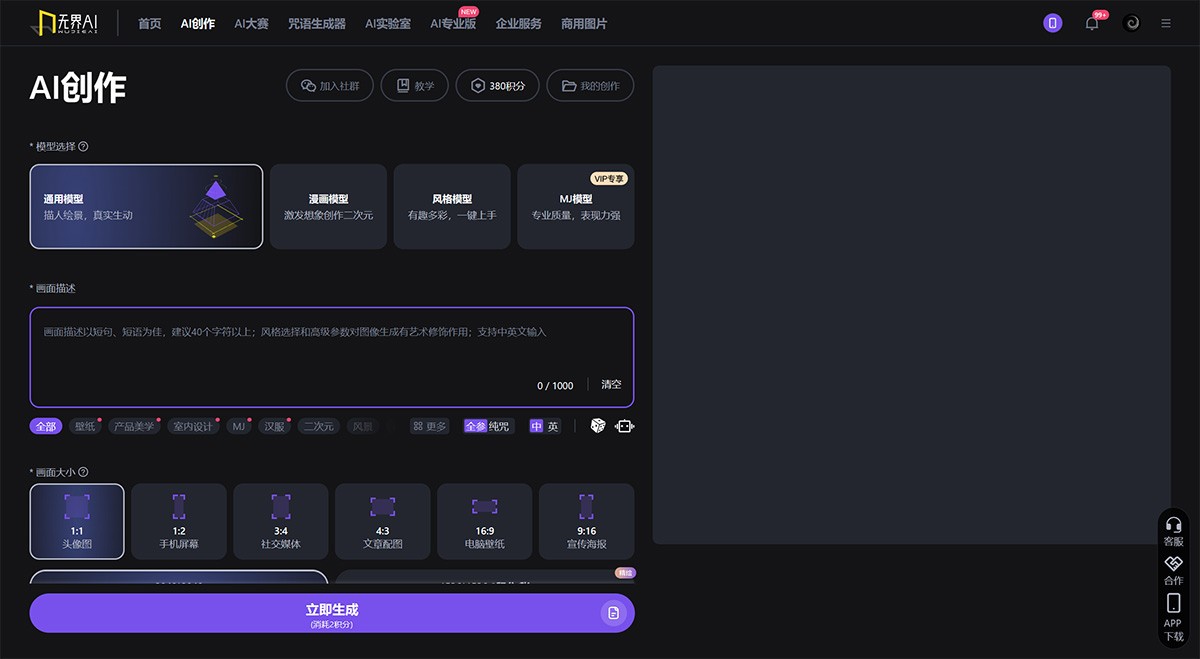
无界AI 无界AI,是一个中文AI绘画工具!集prompt搜索(AI绘画描述词搜索)、AI图库、AI绘画创作、AI广场等为一体的综合AI服务平台。 Ai绘画生成 2025年06月05日 83 点赞 0 评论 571 浏览
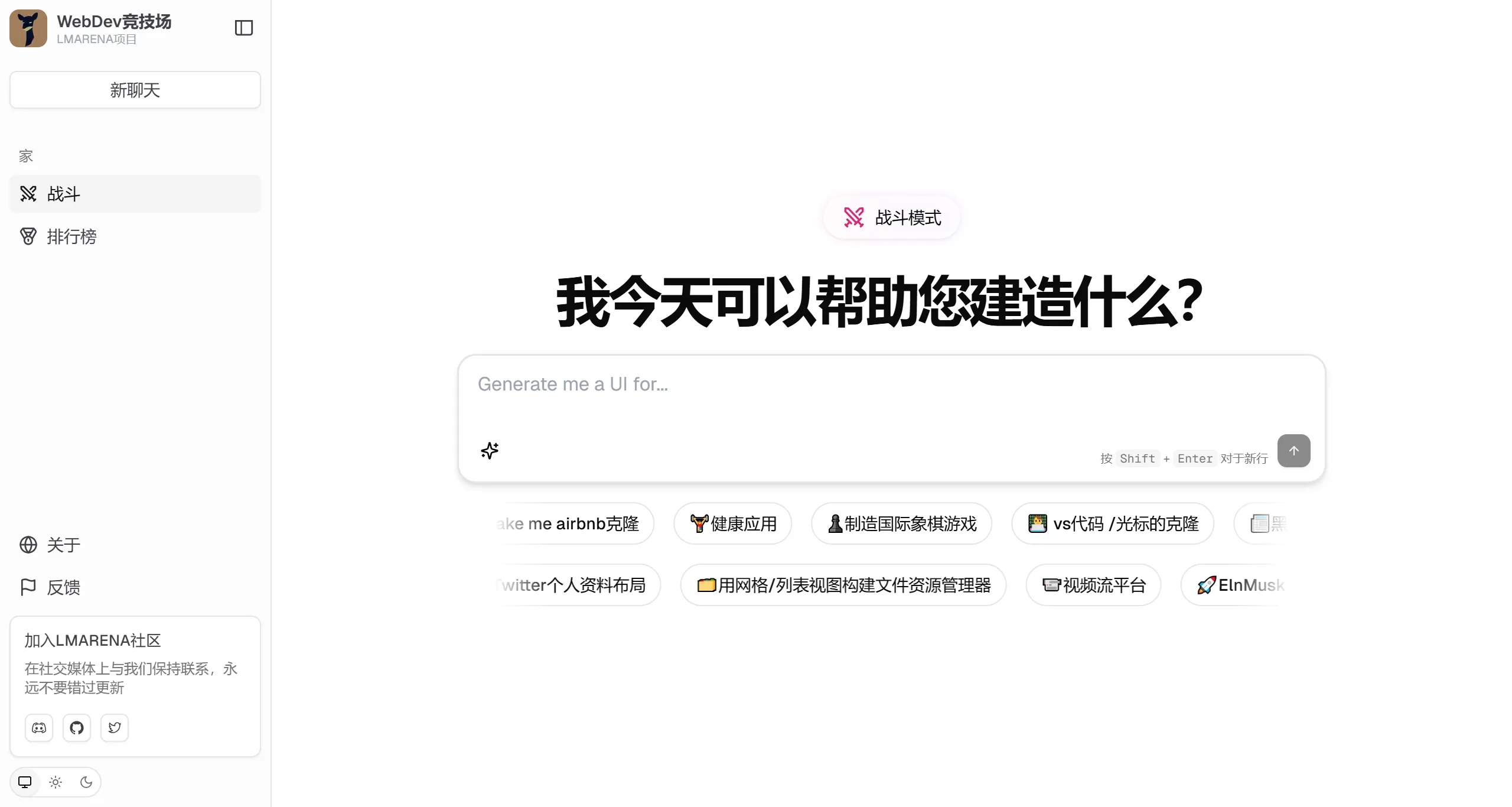
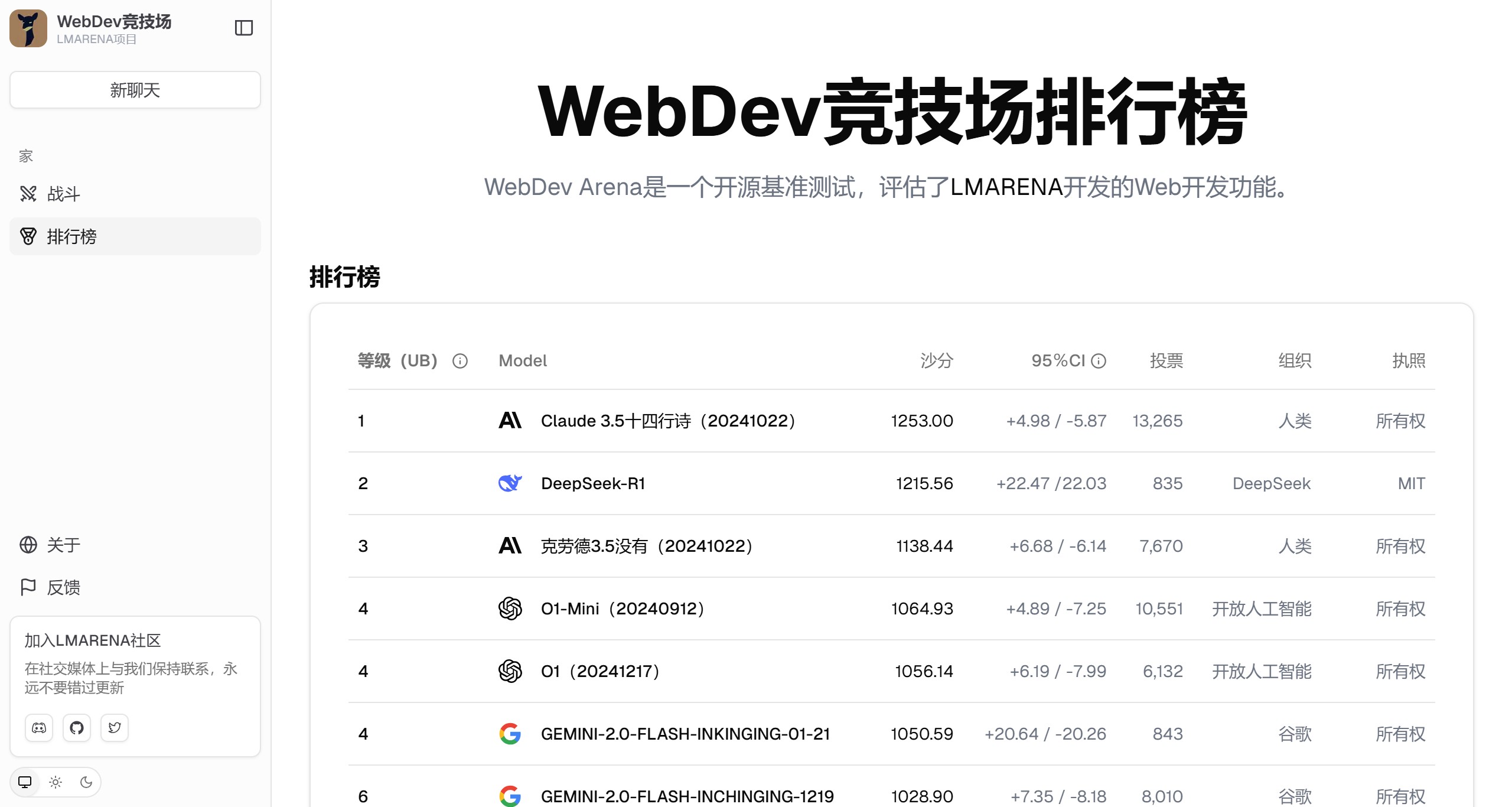
LMArena AI 前身为lmsys.org,是一个专注于众包AI基准测试的开放平台,用户可以在此平台上免费与AI聊天并进行投票,比较和测试不同的AI聊天机器人。 Ai平台模型 2025年06月05日 13 点赞 0 评论 571 浏览
ChatMCP ChatMCP是一款基于模型上下文协议(MCP)的AI聊天客户端,支持与多种大型语言模型(LLM)交互。它提供自动化安装MCP服务器、SSE传输支持、自动选择服务器及聊天记录管理等功能,并通过MCP服务器市场实现与不同数据源的聊天。用户可配置LLM API密钥和端点,界面友好且功能强大,适用于客户服务、个人助理、教育学习、企业内部沟通及信息检索等多种场景。 AI项目与工具 2025年06月12日 48 点赞 0 评论 571 浏览
MewX AI MewX AI是一款集文生图、图生图、艺术二维码生成及室内设计于一体的生成式AI平台,支持多种风格的艺术创作与设计任务。主要功能包括MX绘画、MX Cute、MJ绘画、边缘检测和室内设计,广泛应用于艺术创作、平面设计、插画制作等领域。用户可以通过简洁的操作流程快速生成高质量图像,并灵活调整参数以满足个性化需求。 AI项目与工具 2025年06月12日 52 点赞 0 评论 571 浏览
Wan2.1 Wan2.1是阿里云推出的开源AI视频生成模型,支持文生视频与图生视频,具备复杂运动生成和物理模拟能力。采用因果3D VAE与视频Diffusion Transformer架构,性能卓越,尤其在Vbench评测中表现领先。提供专业版与极速版,适应不同场景需求,已开源并支持多种框架,便于开发与研究。 AI项目与工具 2025年06月12日 47 点赞 0 评论 570 浏览