Objaverse-3D物体数据集 Objaverse 是一个为3D领域提供巨大资源的数据库,它不仅支持 AI 模型的训练和3D内容的生成,还与流行的3D编辑软件 Blender 兼容。 Ai绘画生成 2026年07月29日 0 点赞 0 评论 747 浏览
DINO DINO-X是一款由IDEA研究院开发的通用视觉大模型,具备开放世界对象检测与理解的能力。它支持多种提示类型,无需用户额外输入即可识别图像中的任意对象,并在多个基准测试中刷新了性能记录。DINO-X拥有Pro和Edge两个版本,分别针对高性能需求和边缘设备优化。其应用范围涵盖自动驾驶、智能安防、工业检测及机器人视觉等领域,助力行业创新与发展。 AI项目与工具 2025年06月12日 91 点赞 0 评论 748 浏览
EPLB EPLB是DeepSeek推出的专家并行负载均衡工具,用于优化大规模模型训练中的资源分配。它通过冗余专家策略和分层/全局负载均衡机制,提升GPU利用率和训练效率。支持多层MoE模型,减少通信开销,适应不同场景需求。 AI项目与工具 2025年06月12日 10 点赞 0 评论 748 浏览
MeteoRA MeteoRA是一种基于LoRA和混合专家架构的多任务嵌入框架,用于大型语言模型。它支持多任务适配器集成、自主任务切换、高效推理及复合任务处理,提升模型灵活性和实用性。通过动态门控机制和前向加速策略,显著提高推理效率并降低内存占用,适用于多领域问答、多语言对话等场景。 AI项目与工具 2025年06月12日 72 点赞 0 评论 748 浏览
LangManus LangManus 是一款基于多智能体系统的 AI 自动化框架,支持多种语言模型和 API 接口,具备高效的网络与神经搜索能力。框架内含多种智能体协同工作,可完成任务分配、规划、执行与报告生成。支持代码编写与执行、任务可视化及实时监控,适用于人力资源、房产决策、旅行规划、内容创作和教育开发等多个领域。 AI项目与工具 2025年04月08日 15 点赞 0 评论 748 浏览
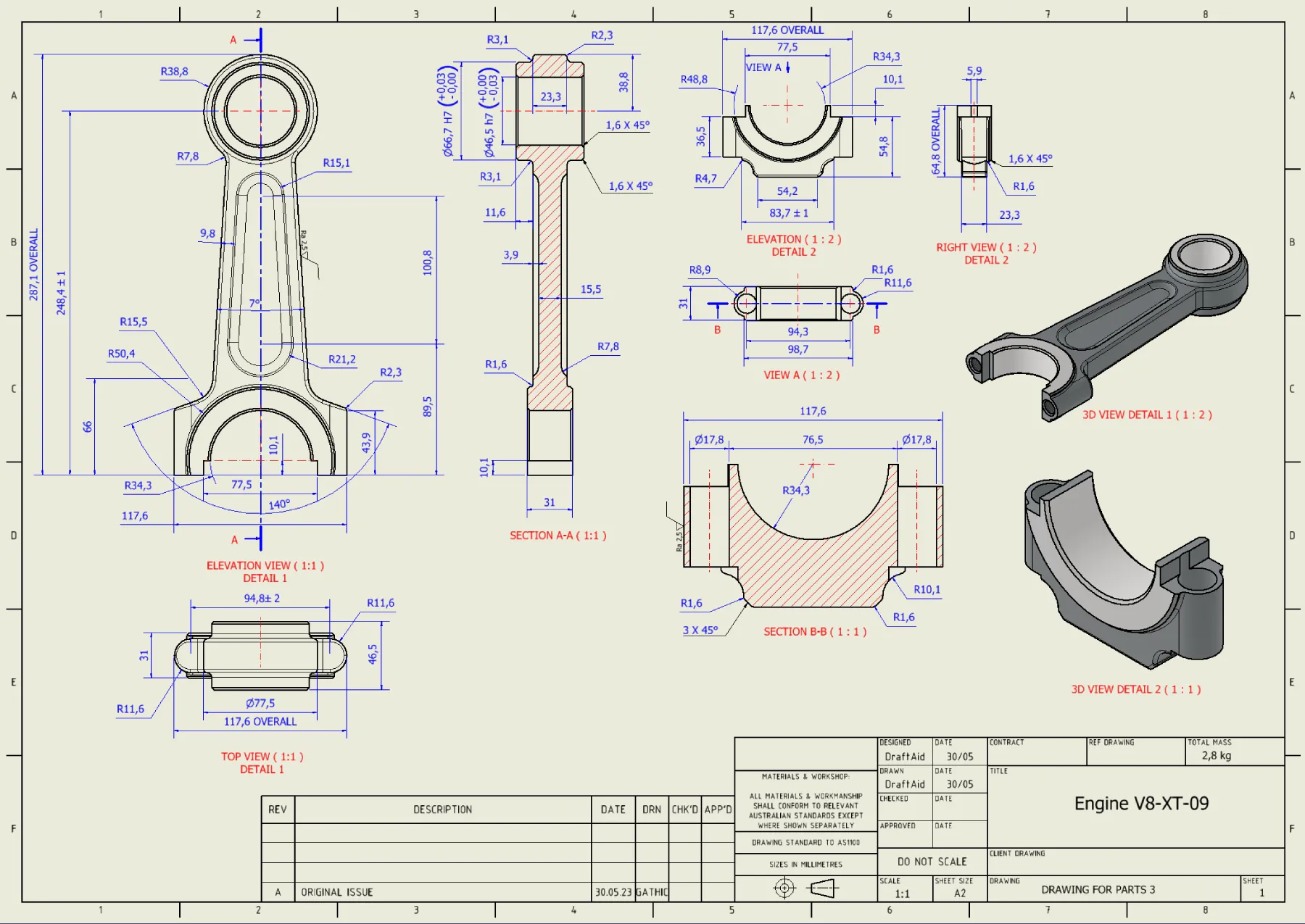
Draftaid 一款能够将3D模型快速转换为高质量的CAD设计图纸的自动化AI生成工具,DraftAid大大幅缩短制图时间,从数小时缩短到几分钟。 3D&游戏 2025年06月05日 73 点赞 0 评论 749 浏览
CogAgent CogAgent是一款由清华大学与智谱AI联合开发的多模态视觉大模型,专注于图形用户界面(GUI)的理解与导航。它具备视觉问答、视觉定位、GUI Agent、高分辨率图像处理及多模态能力,可应用于自动化测试、智能交互、多模态人工智能应用开发、企业级AI Agent平台等多个领域。CogAgent在多个基准测试中表现出色,尤其在GUI操作数据集上显著超越现有模型。 AI项目与工具 2025年06月12日 66 点赞 0 评论 749 浏览
蜜巢政务大模型 蜜巢为蜜度自主研发的政务大模型,在研发工作中,构建了Token数超1万亿、中文内容占比超75%的高质量语料数据集用于预训练工作。 创作工具 2026年07月29日 0 点赞 0 评论 749 浏览
EfficientTAM EfficientTAM是一款由Meta AI研发的轻量级视频对象分割与跟踪模型,基于非层次化Vision Transformer(ViT)构建,通过引入高效记忆模块显著降低了计算复杂度。它能够实现高质量的视频对象分割与多目标跟踪,同时保持较低的延迟和较小的模型尺寸,特别适用于移动设备上的实时视频处理。该模型已在多个视频分割基准测试中表现出色,并支持多种应用场景,包括移动视频编辑、视频监控、增强现 AI项目与工具 2025年06月12日 65 点赞 0 评论 749 浏览
Miras Miras是由谷歌开发的深度学习框架,专注于序列建模任务。它基于关联记忆和注意力偏差机制,整合多种序列模型并支持新型模型设计。Miras通过保留门机制优化记忆管理,提升模型在长序列任务中的表现,适用于语言建模、常识推理、长文本处理及多模态任务,具有高效且灵活的架构优势。 AI项目与工具 2025年06月11日 58 点赞 0 评论 749 浏览