模型





Whisper语音识别模型
Whisper 是一种通用的语音识别模型。它在不同音频的大型数据集上进行训练,也是一个多任务模型,可以执行多语言语音识别以及语音翻译和语言识别。


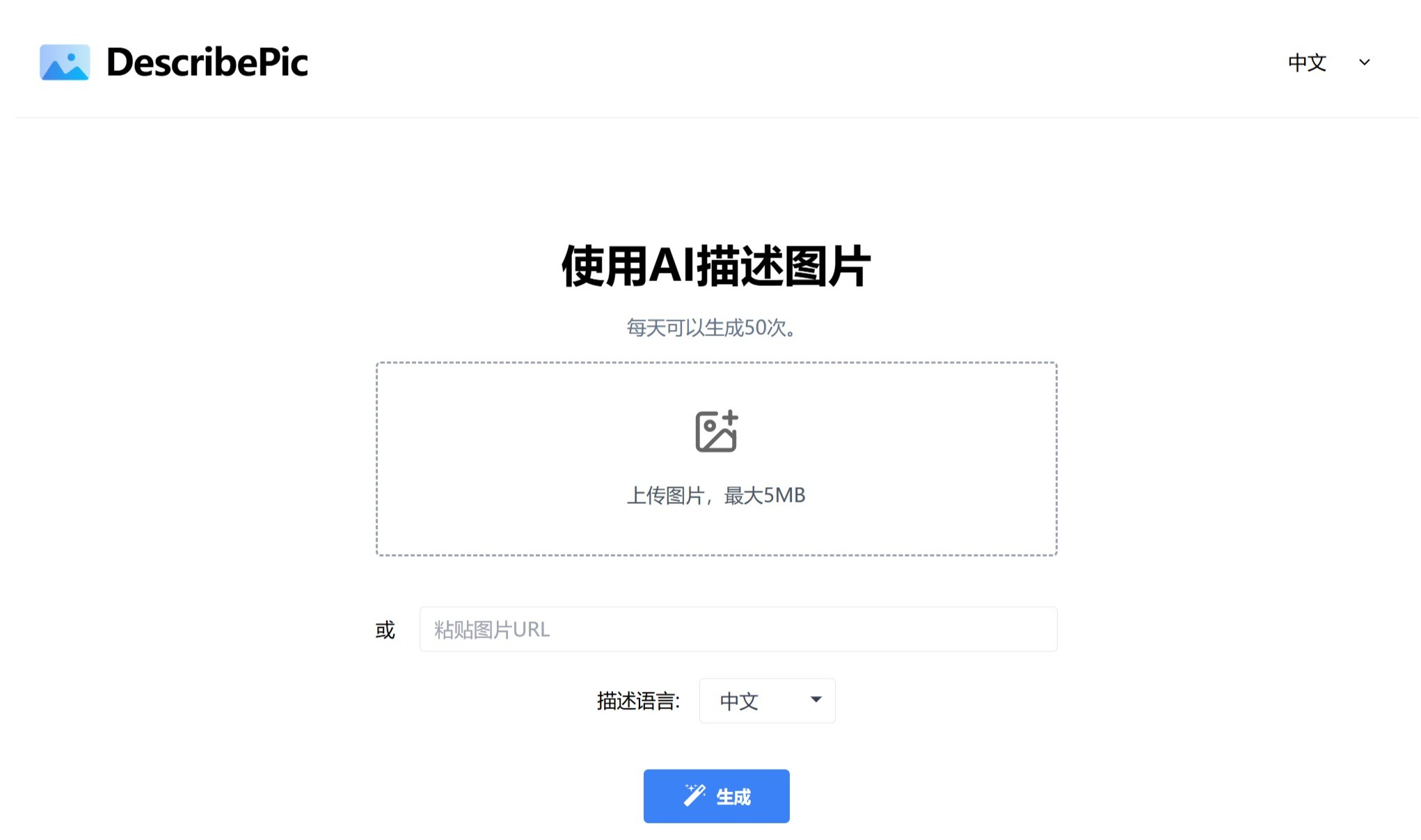


Reverb ASR
Reverb ASR是一款基于深度学习的开源自动语音识别与说话人分离工具,采用20万小时高质量英语语音数据训练,具备高精度语音转录能力,支持逐字稿控制及多种解码模式。其显著特点是擅长处理长时间语音内容,并在长篇幅识别任务中超越其他开源模型。Reverb ASR适用于播客、会议记录、法庭记录等多个应用场景,为用户提供灵活且高效的语音转文字解决方案。

