Eagle Eagle是一个由英伟达开发的多模态大模型,专长于处理高分辨率图像,提高视觉问答和文档理解能力。该模型采用多专家视觉编码器架构,通过简单的特征融合策略实现图像内容的深入理解。Eagle模型已开源,适用于多个行业,具有高分辨率图像处理、多模态理解、多专家视觉编码器、特征融合策略和预对齐训练等特点。 AI项目与工具 2025年06月12日 38 点赞 0 评论 532 浏览
All GPTs All GPTs目录是一个综合性在线资源,列出了各种GPT(预训练生成式转换器)模型、AI代理和应用程序。它是一个集中的地方,可以找到和探索基于AI的解决方案。 GPTs应用 2025年06月05日 76 点赞 0 评论 530 浏览
零沫AI工具导航 一个AI垂直类交流社区,一直专注AI领域发展,零沫AI收录了国内外数百个不同类型的AI工具,每日更新和添加最新AI工具。 Ai学习资源 2025年06月05日 13 点赞 0 评论 530 浏览
极客编辑器 极客编辑器是一款所见即所得富文本沉浸式写作排版编辑器,它注重高效创作,可多开文档编辑,同时支持Markdown语法输入及一键排版。 排版编辑 2025年06月05日 21 点赞 0 评论 529 浏览
百聆 百聆是一款开源语音对话系统,融合语音识别、语音活动检测、大语言模型和语音合成技术,实现自然流畅的语音交互。支持低延迟运行,无需GPU,适用于边缘设备。具备记忆、工具调用和任务管理等功能,适用于智能家居、个人助理、车载系统等多种场景,提供高效的语音交互解决方案。 AI项目与工具 2025年06月12日 90 点赞 0 评论 529 浏览
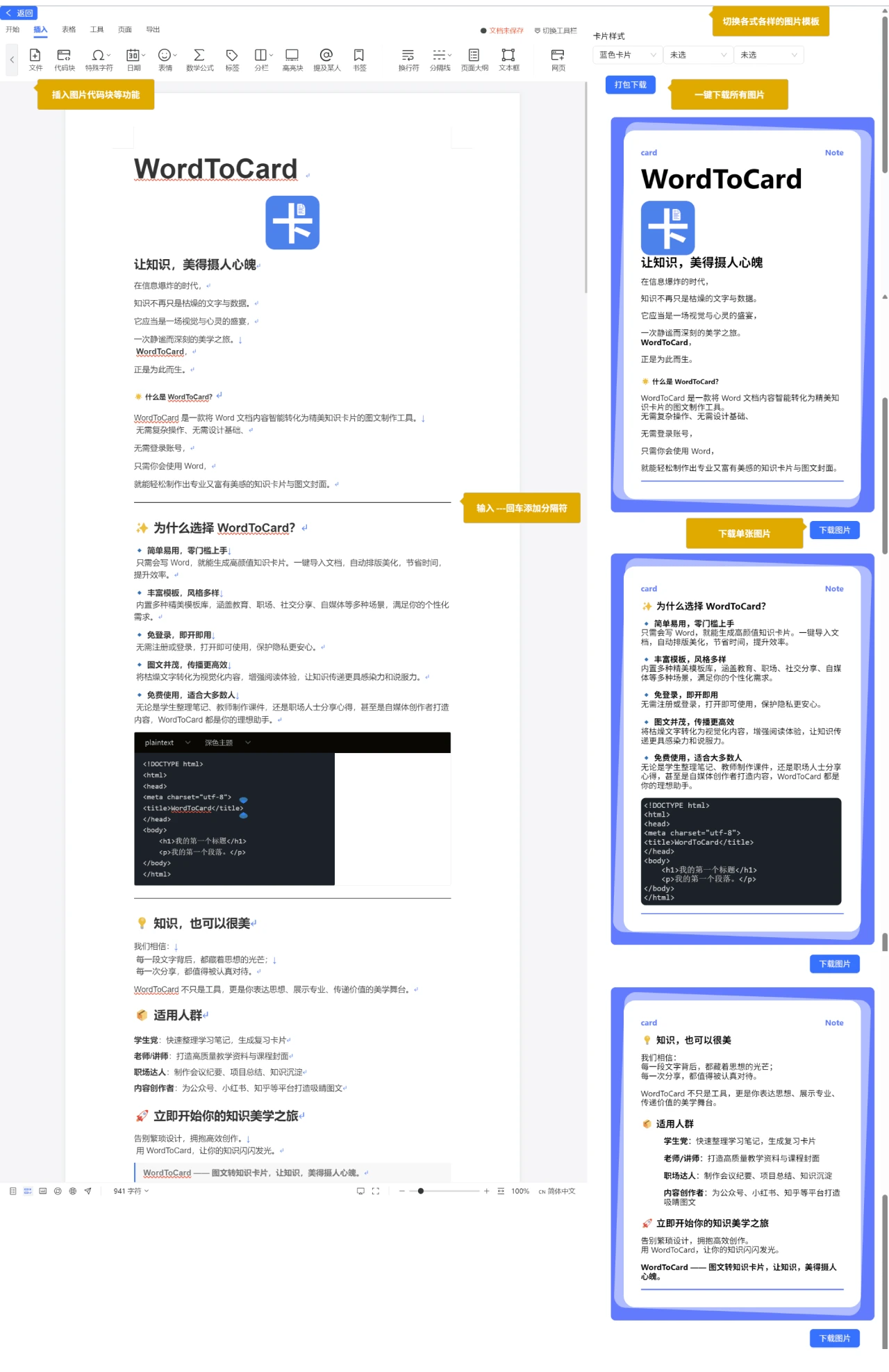
WordToCard 一个能将Word文档内容智能转化为精美知识卡片的图文制作开源免费工具,能将 Word 文档自动转换为结构清晰、美观大方的图文卡片。 排版编辑 2025年06月05日 79 点赞 0 评论 528 浏览
Klavis AI Klavis AI 是一个基于 MCP 协议的开源平台,提供稳定可靠的 MCP 服务器和多客户端集成能力。支持多种工具定制化配置,内置身份验证功能,保障安全性。平台采用分布式架构,适用于大规模用户场景,并通过 API 实现灵活部署与管理,适用于 AI 开发、数据处理、内容创作及企业协作等多种应用场景。 AI项目与工具 2025年06月11日 23 点赞 0 评论 528 浏览
Qwen3 Qwen3 是阿里巴巴推出的下一代大型语言模型,支持“思考模式”和“非思考模式”,适用于复杂与简单任务。具备 119 种语言支持,优化了编码与 Agent 能力,数据量达 36 万亿 token,采用四阶段训练流程。提供多种模型配置,涵盖从轻量级到企业级应用。在多项基准测试中表现优异,广泛应用于文本生成、机器翻译、法律文书、技术文档、医疗辅助等领域。 AI项目与工具 2025年06月11日 11 点赞 0 评论 527 浏览
Qwen2 Qwen2是由阿里云通义千问团队开发的大型语言模型系列,涵盖从0.5B到72B的不同规模版本。该系列模型在自然语言理解、代码编写、数学解题及多语言处理方面表现出色,尤其在Qwen2-72B模型上,其性能已超过Meta的Llama-3-70B。Qwen2支持最长128K tokens的上下文长度,并已在Hugging Face和ModelScope平台上开源。 --- AI项目与工具 2024年01月01日 48 点赞 0 评论 526 浏览
书生·筑梦2.0(Vchitect 2.0) 书生·筑梦2.0是一款由上海人工智能实验室开发的开源视频生成大模型,支持文本到视频和图像到视频的转换,生成高质量的2K分辨率视频内容。它具备灵活的宽高比选择、强大的超分辨率处理能力以及创新的视频评测框架,适用于广告、教育、影视等多个领域。 AI项目与工具 2025年06月12日 32 点赞 0 评论 524 浏览