开源

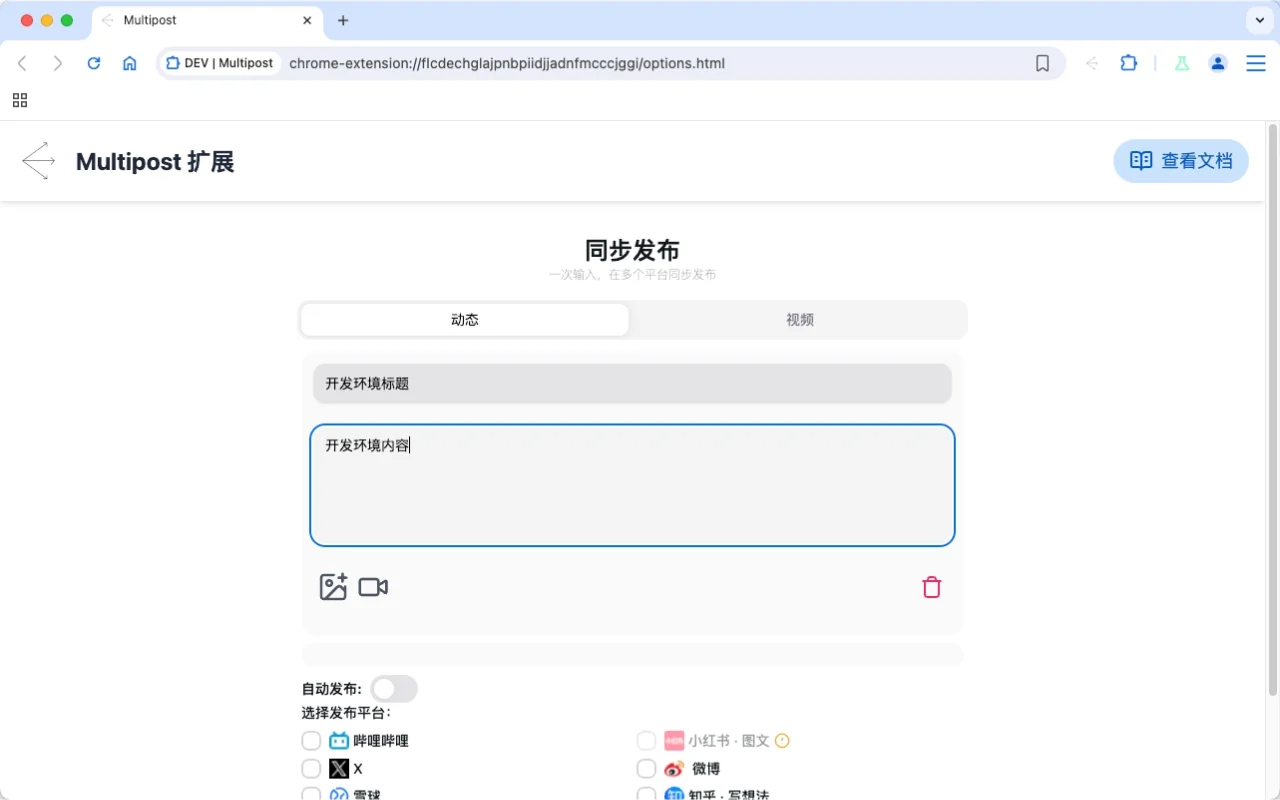
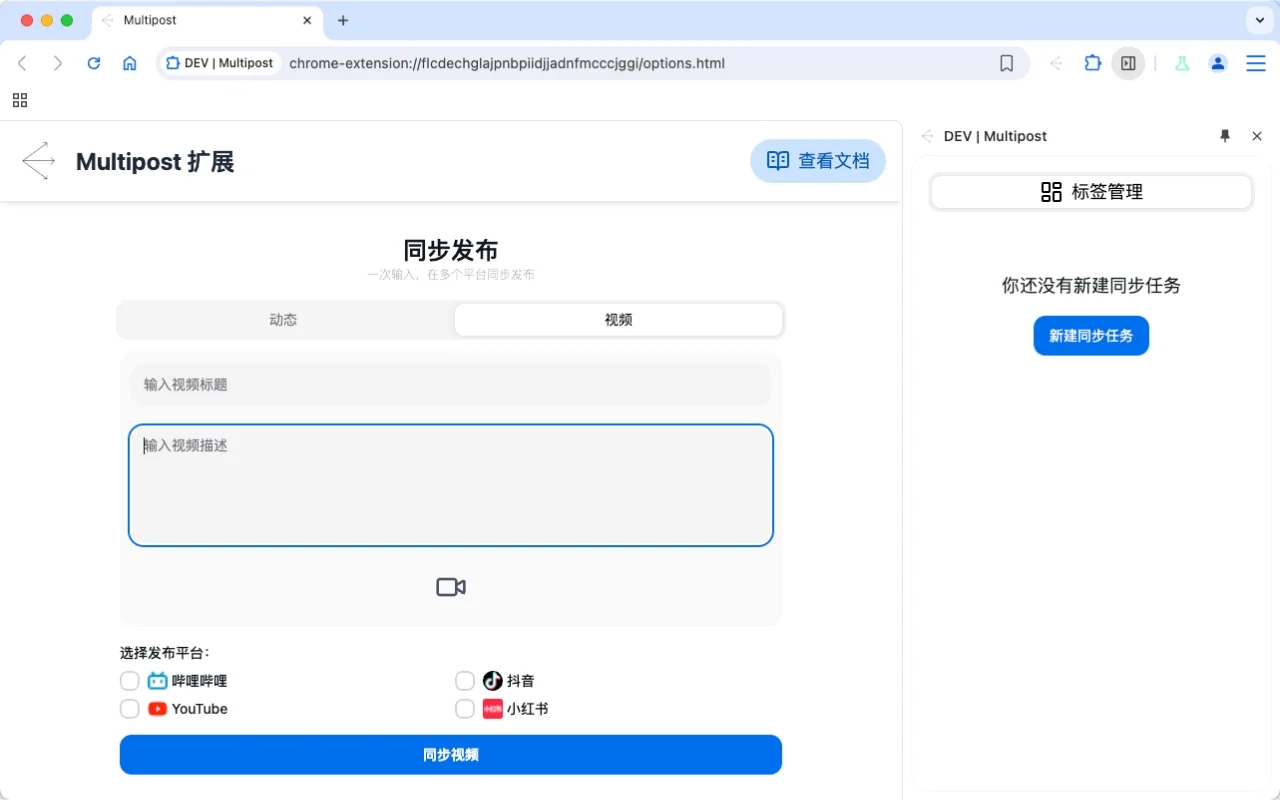





Nanobrowser
Nanobrowser 是一款开源的 Chrome 扩展工具,采用多智能体系统实现网页自动化任务,如信息提取和操作执行。用户可通过 LLM API 配置不同智能体,提升任务灵活性。支持本地运行,保障隐私安全,适用于信息收集、电商、内容创作、企业自动化和个人效率提升等多种场景。其动态调整机制增强了任务的稳定性和适应能力。


