TheoremExplainAgent TheoremExplainAgent(TEA)是一款基于多模态技术的AI工具,可生成超过5分钟的数学与科学定理解释视频,涵盖多个STEM领域。它结合文本、动画和语音,提升抽象概念的理解效果,并具备自动错误诊断功能。通过TheoremExplainBench基准评估,TEA在准确性、逻辑性和视觉表现上均表现优异,适用于在线教育、课堂教学和学术研究等多种场景。 AI项目与工具 2025年06月12日 13 点赞 0 评论 815 浏览
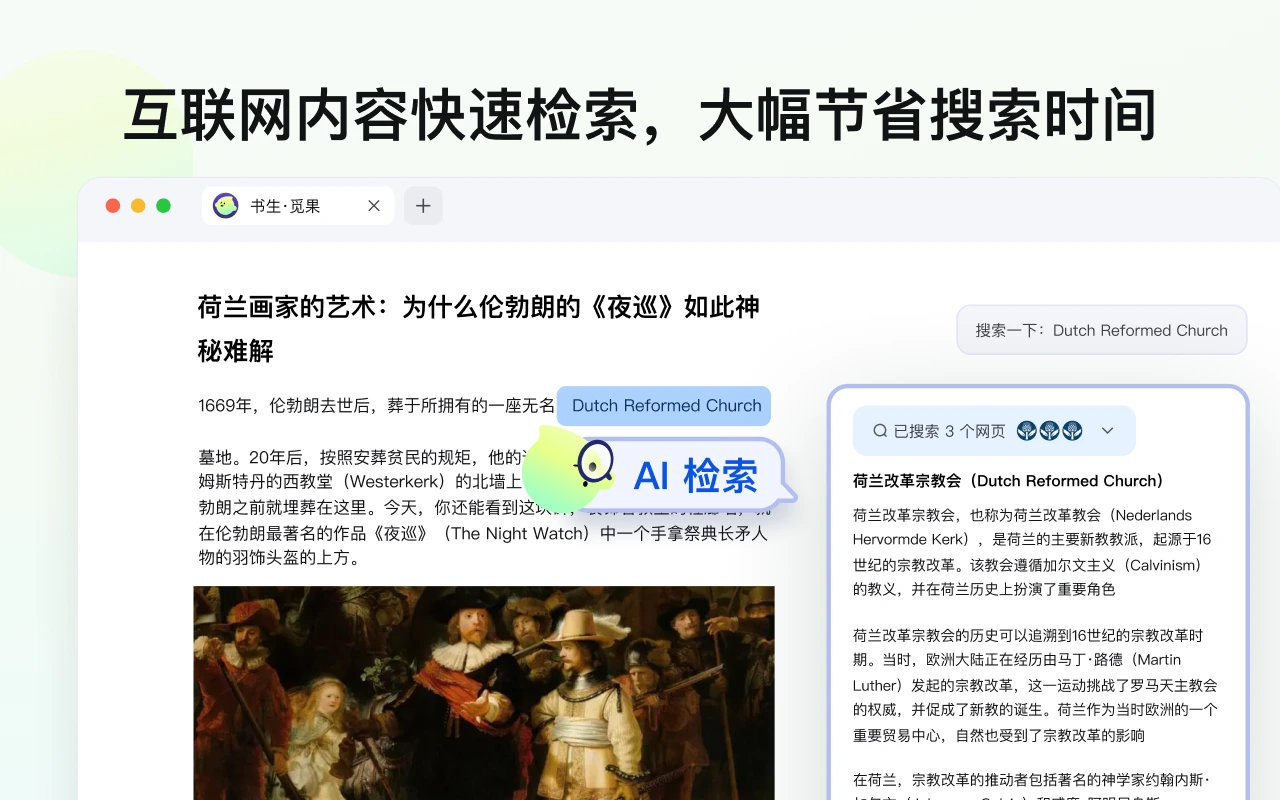
觅果Migo 一款AI学习办公助手。为用户提供便捷、高效的文字处理、信息搜索、知识问答等支持,还能辅助论文阅读、润色学术写作,支持多模态交互。 AI写作对话 2025年06月05日 85 点赞 0 评论 815 浏览
SOLAMI SOLAMI是一款基于VR环境的3D角色扮演AI系统,支持用户通过语音和肢体语言与虚拟角色进行沉浸式互动。系统采用社交视觉-语言-行为模型(Social VLA),可识别用户的多模态输入并生成相应响应,涵盖多种角色类型及互动场景,如游戏、舞蹈等。其核心技术涉及多任务预训练和指令微调,适用于虚拟社交、教育、心理治疗及娱乐等多个领域。 AI项目与工具 2025年06月12日 66 点赞 0 评论 815 浏览
童语故事iMageStoryAi 一个基于数字分身和故事模型的AI儿童故事生成类Al产品,童语故事iMageStoryAi通过Al能力创造无限的潜能,让每个孩子健康快乐成长。 Ai绘画生成 2025年06月05日 93 点赞 0 评论 814 浏览
LEOPARD LEOPARD是一款由腾讯AI Lab开发的视觉语言模型,专为处理包含大量文本的多图像任务而设计。它通过自适应高分辨率多图像编码模块和大规模多模态指令调优数据集,实现对复杂视觉语言任务的高效处理,包括跨图像推理、高分辨率图像处理及动态视觉序列长度优化。LEOPARD在自动化文档理解、教育、商业智能等领域具有广泛应用潜力。 AI项目与工具 2025年06月12日 35 点赞 0 评论 814 浏览
VE VE-Bench是北京大学MMCAL团队研发的一款视频编辑质量评估工具,包含数据库(VE-Bench DB)和量化评估模块(VE-Bench QA)。它综合考虑了视觉质量、文本-视频一致性及源视频与编辑后视频的动态关联性,旨在实现与人类感知一致的精准评估。适用于电影制作、短视频优化、广告行业等多个领域。 AI项目与工具 2025年06月12日 12 点赞 0 评论 814 浏览
TextHarmony TextHarmony是一款由华东师范大学与字节跳动联合开发的多模态生成模型,擅长视觉与文本信息的生成与理解。该模型基于Slide-LoRA技术,支持视觉文本生成、编辑、理解及感知等功能,广泛应用于文档分析、场景文本识别、视觉问题回答、图像编辑与增强以及信息检索等领域。通过高质量数据集的构建与多模态预训练,TextHarmony在视觉与语言生成任务中表现出色。 AI项目与工具 2025年06月12日 47 点赞 0 评论 813 浏览
Migician Migician是一款由多所高校联合开发的多模态大语言模型,专为多图像定位任务设计。它基于大规模数据集MGrounding-630k,采用端到端架构和两阶段训练方法,支持跨图像精准定位与多任务处理。Migician适用于自动驾驶、安防监控、医疗影像等多个领域,具有高效的推理能力和灵活的输入方式。 AI项目与工具 2025年06月12日 90 点赞 0 评论 813 浏览
MinerU MinerU是一款开源智能数据提取工具,专注于复杂PDF文档的高效解析与提取。它能够将包含多种内容类型的PDF文档转换为结构化的Markdown格式,支持图像、公式、表格和文本等多种内容处理,保留原始文档结构和格式,支持公式识别与转换成LaTeX格式,自动删除页眉、页脚、脚注和页码等非内容元素,适用于学术、财务、法律等多个领域。 AI项目与工具 2025年06月12日 92 点赞 0 评论 811 浏览
Claude 4 Claude 4 是 Anthropic 公司推出的新一代 AI 模型,包括 Claude Opus 4 和 Claude Sonnet 4。Claude Opus 4 擅长复杂任务和长时间运行的工作流,如代码生成、优化和调试,具有强大的推理能力。Claude Sonnet 4 在编程和推理上表现优异,适合日常使用。两者均支持工具使用、记忆管理、多模态处理等功能,提升 AI Agent 的效率与实 AI项目与工具 2025年06月11日 36 点赞 0 评论 809 浏览