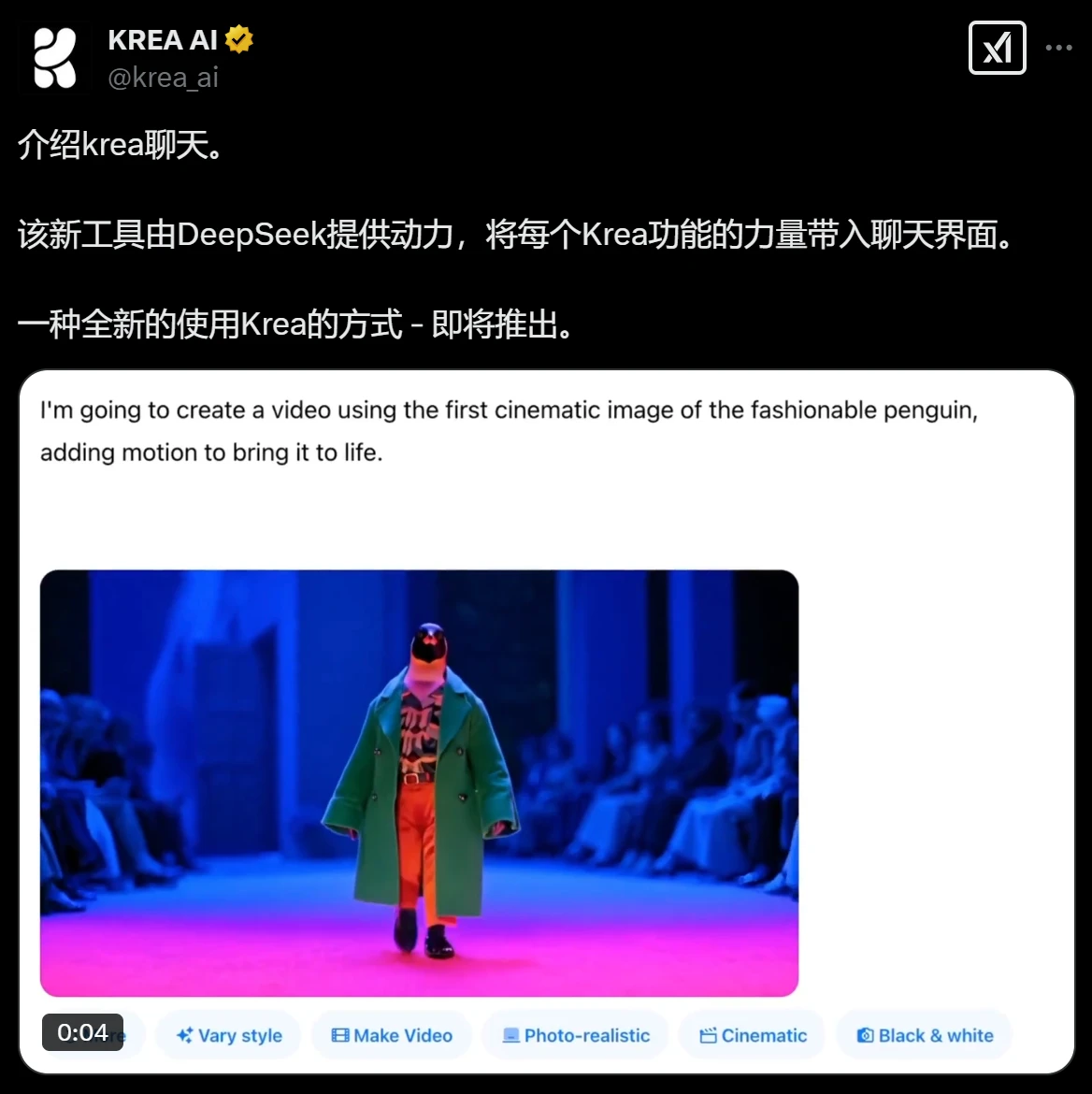
图像


Ideogram 2a
Ideogram 2a 是 AI 图像生成平台 Ideogram 推出的文生图模型,基于 Ideogram 2.0 优化升级,具备高效生成、成本降低、高质量文本渲染等特点。支持多种艺术风格和中文提示,适用于平面设计、数字营销、摄影及艺术创作等多个领域,是提升图像创作效率和质量的实用工具。



LeiaPix Converter
LeiaPix Converter是其旗下一款由AI技术驱动的免费在线图像处理工具,可帮助用户一键将静态的2D图像转换为动态3D

VideoAnydoor
VideoAnydoor是一款由多所高校与研究机构联合开发的视频对象插入系统,基于文本到视频的扩散模型,支持高保真对象插入与精确运动控制。其核心模块包括ID提取器和像素变形器,能实现对象的自然融合与细节保留。该工具适用于影视特效、虚拟试穿、虚拟旅游、教育等多个领域,具备良好的通用性和扩展性。