图像



Freeflo.ai
Freeflo.ai 是一个多功能的 AI 绘画辅助平台,它通过提供丰富的风格提示词和直观的样例图像,极大地丰富了 AI 绘画的创作可能性。
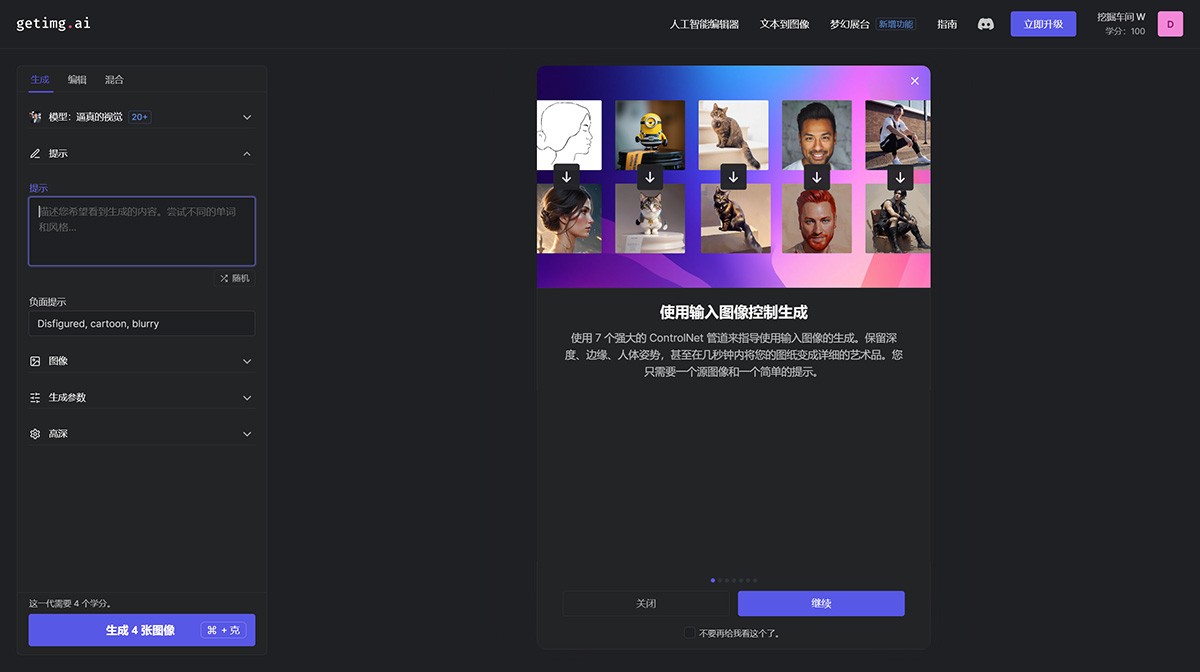


Minister AI
Minister AI是一款免费使用的AI绘图工具,登录即用的在线Stable Diffusion,支持海量模型上传下载。

Chatbox AI
Chatbox AI是一款开源跨平台AI助手,支持多语言模型集成与本地部署,提供图像生成、代码辅助、文档交互等功能。用户可自由定制并参与社区开发,确保数据安全与隐私保护,适用于办公、学习、开发等多种场景,提升工作效率与创意表达。



Interior AI
Interior AI是一个人工智能图像生成器平台,允许用户上传自己(或其他人)家的图像,并根据17种预选风格之一生成新的外观和布局。它是日益增长的人工智能图像生成器生态系统的一部分...
