图像



AnimateDiff
AnimateDiff是一款由上海人工智能实验室、香港中文大学和斯坦福大学的研究人员共同开发的框架,旨在将文本到图像模型扩展为动画生成器。该框架利用大规模视频数据集中的运动先验知识,允许用户通过文本描述生成动画序列,无需进行特定的模型调优。AnimateDiff支持多种领域的个性化模型,包括动漫、2D卡通、3D动画和现实摄影等,并且易于与现有模型集成,降低使用门槛。


AddressCLIP
AddressCLIP 是一种基于 CLIP 技术的端到端图像地理定位模型,由中科院自动化所与阿里云联合开发。它通过图像与地址文本对齐和地理匹配技术,实现街道级别的精确定位,无需依赖 GPS。模型在多个数据集上表现优异,适用于城市管理、社交媒体、旅游导航等多个场景,具备良好的灵活性和多模态结合潜力。

AI Interview Copilot
AI Interview Copilot是一款专为求职者设计的AI辅助工具,通过实时语音转录和先进的语言模型(如GPT-4)来提升远程面试的表现。主要功能包括实时转录、问题解答、算法问题解决和图像识别等。该工具支持多语言,帮助求职者在技术或编程面试中快速生成答案和代码,从而更加自信地展示专业技能,提高面试成功率。


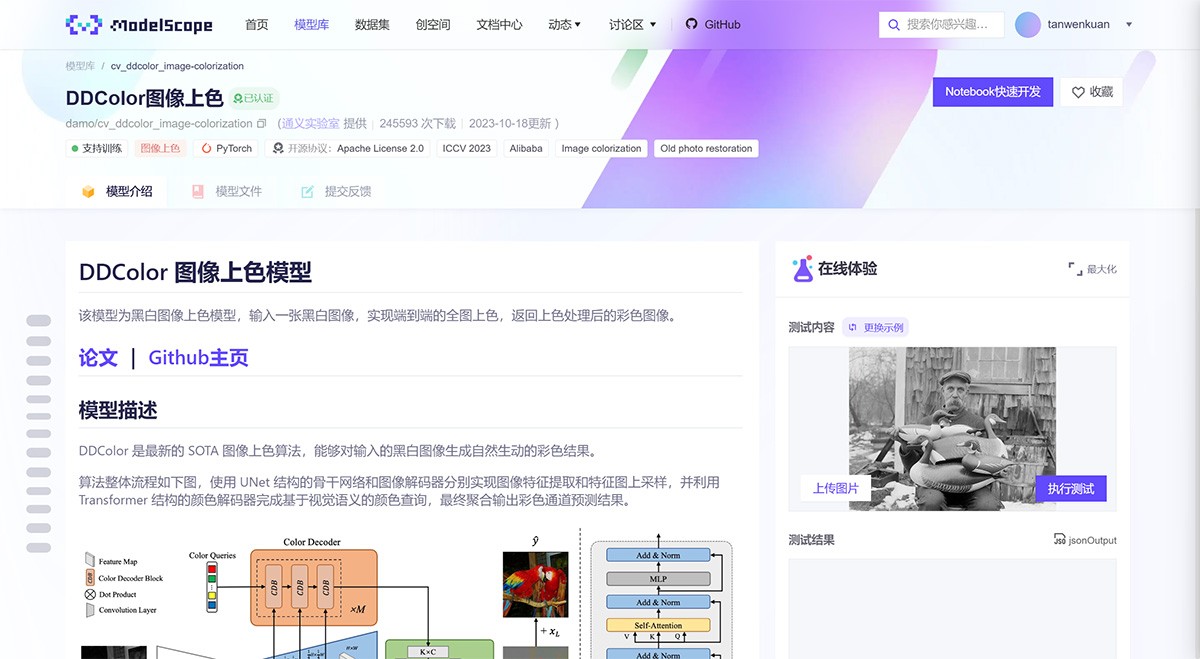



PersonaCraft
PersonaCraft是一种结合扩散模型和3D人体建模的全身图像合成技术,能够从单一参考图像生成多个逼真的个性化全身图像。它支持遮挡处理、用户自定义身体形状,并通过3D感知姿态条件控制提高生成图像的质量。该工具广泛应用于社交媒体、广告、时尚、游戏及电影等领域,为个性化定制提供了强大的技术支持。
