PlayDiffusion PlayDiffusion是Play AI推出的音频编辑模型,基于扩散模型技术实现音频的精细编辑和修复。它将音频编码为离散标记序列,通过掩码处理和去噪生成高质量音频,保持语音连贯性和自然性。支持局部编辑、高效文本到语音合成、动态语音修改等功能,具有非自回归特性,提升生成速度与质量。适用于配音纠错、播客剪辑、实时语音互动等场景。 AI项目与工具 2025年06月11日 94 点赞 0 评论 882 浏览
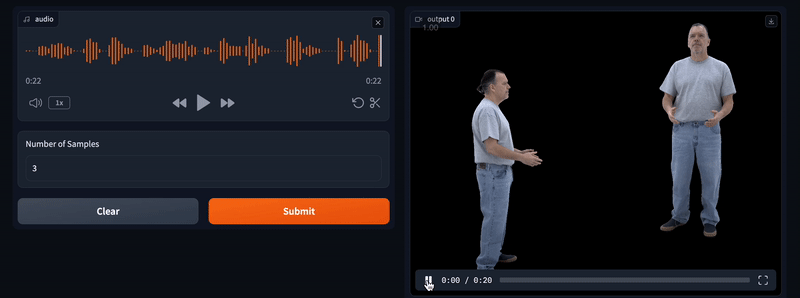
Audio2Photoreal 从音频生成全身逼真的虚拟人物形象。它可以从多人对话中语音中生成与对话相对应的逼真面部表情、完整身体和手势动作。 Ai开源项目 2025年06月05日 77 点赞 0 评论 588 浏览
VideoPoet VideoPoet是一款基于大模型的AI视频生成工具,支持从文本、图像或视频输入中合成高质量的视频内容及匹配的音频。其核心优势在于多模态大模型设计,能够处理和转换不同类型的输入信号,无需特定数据集或扩散模型即可实现多种风格和动作的视频输出。主要功能包括文本到视频转换、图像到视频动画、视频风格化、视频编辑和扩展、视频到音频转换以及多模态学习等。技术原理涉及多模态输入处理、解码器架构、预训练与任务适应 AI项目与工具 2024年01月01日 98 点赞 0 评论 749 浏览
Grok Grok-1是由xAI公司开发的大型语言模型,具备3140亿参数,是目前参数量最大的开源大语言模型之一。该模型基于Transformer架构,专用于自然语言处理任务,如问答、信息检索、创意写作和编码辅助等。尽管在信息处理方面表现出色,但需要人工审核以确保准确性。此外,Grok-1还提供了8bit量化版本,以降低存储和计算需求。 AI项目与工具 2024年01月01日 10 点赞 0 评论 745 浏览
VoiceCraft VoiceCraft是一款开源的神经编解码器语言模型,专攻零样本语音编辑和文本到语音(TTS)任务。它采用Transformer架构,通过token重排过程结合因果掩蔽和延迟叠加技术,实现在现有音频序列内高效生成自然的语音。VoiceCraft在多种口音、风格和噪声条件下表现出色,适用于有声读物制作、视频内容创作、播客音频编辑及多语言内容生产等场景。 AI项目与工具 2024年01月01日 31 点赞 0 评论 789 浏览
Video Diffusion Models Video Diffusion Models项目展示了扩散模型在视频生成领域的潜力,通过创新的梯度条件方法和自回归扩展技术,生成了具有高度时间连贯性和质量的视频样本。 Ai绘画生成 2026年07月29日 0 点赞 0 评论 626 浏览
StreamingT2V StreamingT2V是由Picsart AI Research等团队联合发布的一款创新的AI视频生成模型。它能生成长达1200帧、时长为2分钟的视频,大大超越了先前模型的时长限制,如Sora模型。Streaming... Ai视频生成 2026年07月29日 0 点赞 0 评论 524 浏览
Voicebox Voicebox 是由 Meta AI 研究团队开发的一款领先的语音生成模型。Voicebox 能够在六种语言中合成语音,消除瞬态噪声,编辑内容,在语言之间转移音频风格,并生成多样的语音样本。此... 创作工具 2026年07月29日 0 点赞 0 评论 835 浏览
Seed Music 一个强大的音乐生成工具,它通过先进的技术手段,如自回归模型和扩散模型,为用户提供了从音乐创作到编辑再到声音转换的全方位服务。这套系统不仅能够生成高质量的音乐作品,还能... 创作工具 2026年07月29日 0 点赞 0 评论 711 浏览