回归







PrimitiveAnything
PrimitiveAnything是由腾讯AIPD与清华大学联合开发的3D形状生成框架,通过将复杂3D形状分解为基本基元并自回归生成,实现高质量、高保真度的3D模型重建。其支持从文本或图像生成内容,具备高效存储、模块化设计及良好的泛化能力,适用于3D建模、游戏开发、UGC创作及VR/AR应用等领域。


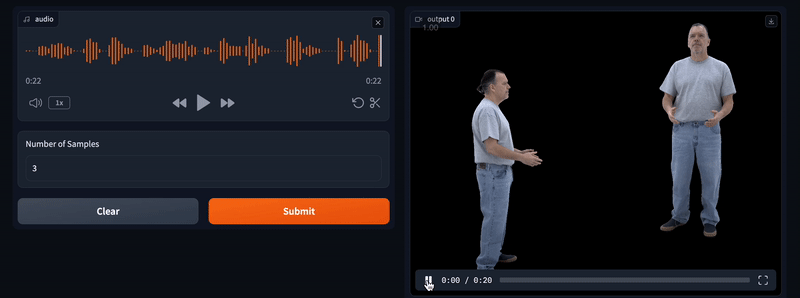
PlayDiffusion
PlayDiffusion是Play AI推出的音频编辑模型,基于扩散模型技术实现音频的精细编辑和修复。它将音频编码为离散标记序列,通过掩码处理和去噪生成高质量音频,保持语音连贯性和自然性。支持局部编辑、高效文本到语音合成、动态语音修改等功能,具有非自回归特性,提升生成速度与质量。适用于配音纠错、播客剪辑、实时语音互动等场景。