OCR




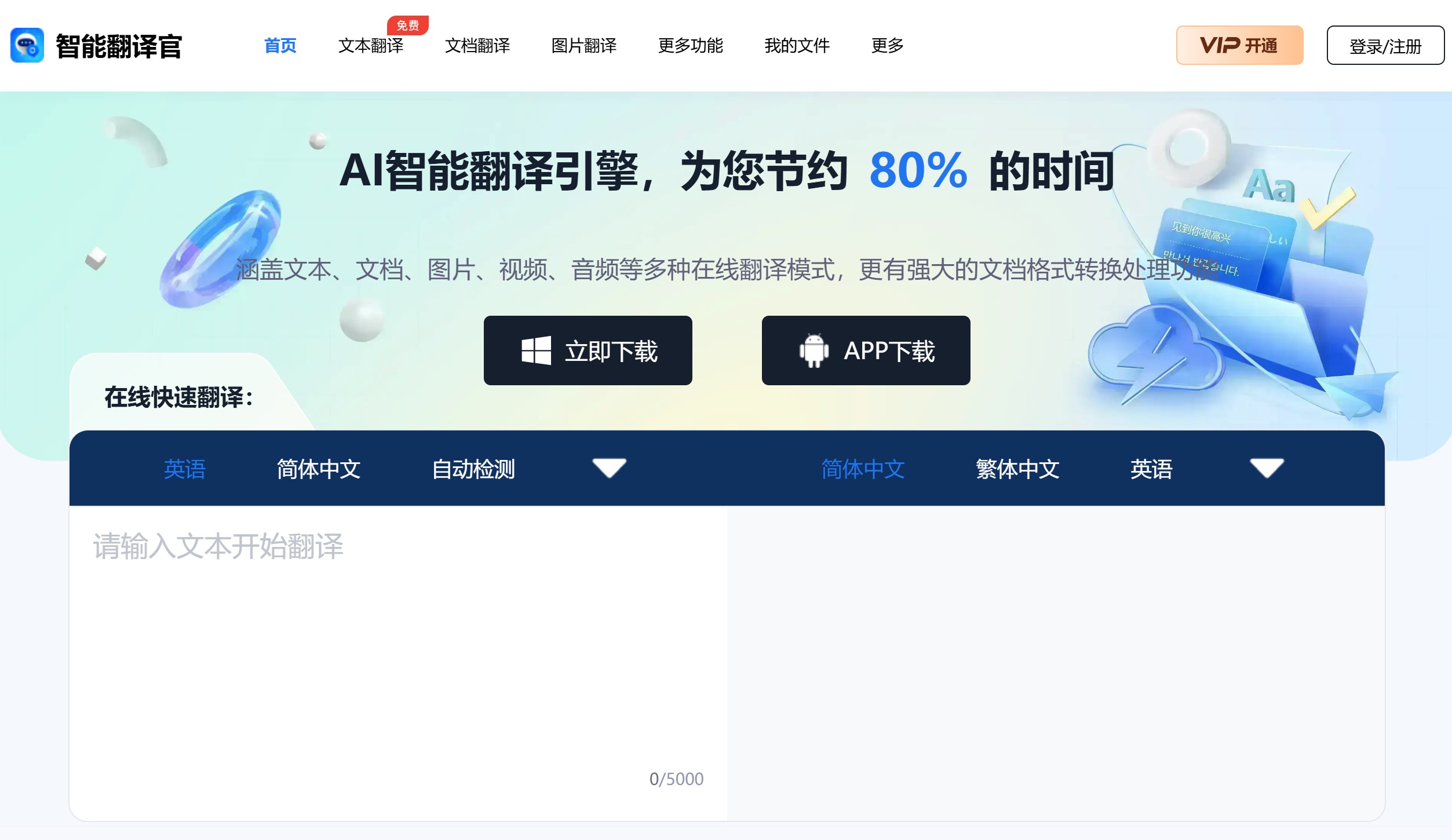

Vision Parse
Vision Parse 是一款开源工具,旨在通过视觉语言模型将 PDF 文件转换为 Markdown 格式。它具备智能识别和提取 PDF 内容的能力,包括文本和表格,并能保持原有格式与结构。此外,Vision Parse 支持多种视觉语言模型,确保解析的高精度与高速度。其应用场景广泛,涵盖学术研究、法律文件处理、技术支持文档以及电子书制作等领域。
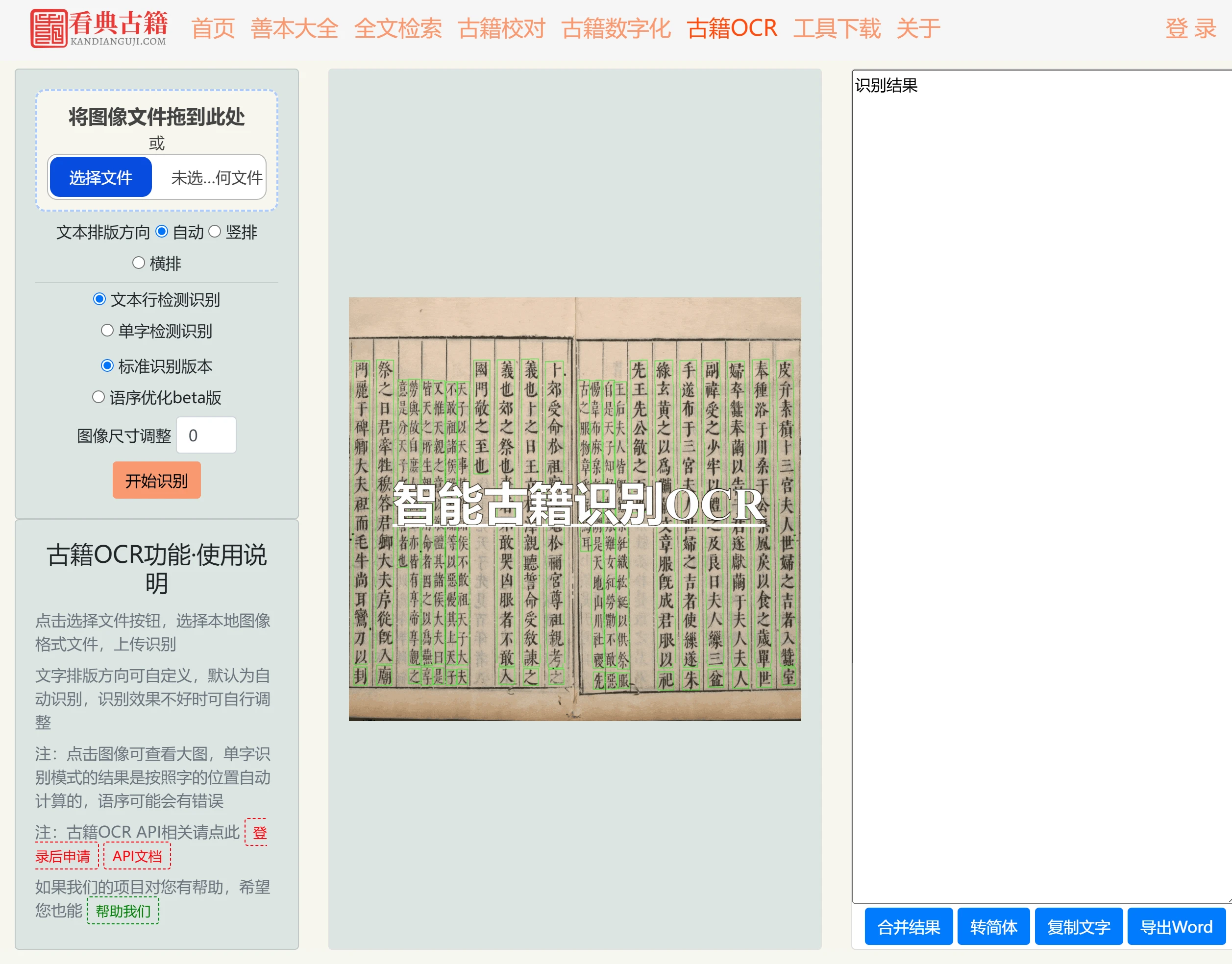



OmniParser
OmniParser是一款由微软研究院开发的屏幕解析工具,能够将UI截图转换为结构化数据,通过识别可交互图标和提取功能语义,提升基于大型语言模型的UI代理系统的性能。它支持跨平台应用,无需依赖额外信息,适用于自动化软件测试、虚拟助手、辅助技术等多个领域。
