AI





Gemini 2.5 Flash
Gemini 2.5 Flash 是 Google 推出的高性能 AI 模型,具备低延迟、高效率及推理能力,适用于代码生成、智能代理和复杂任务处理。其优化设计降低了计算成本,适合大规模部署。该模型基于 Transformer 架构,结合推理机制和模型压缩技术,提升了响应速度与准确性,广泛应用于智能开发、内容生成和实时交互等领域。

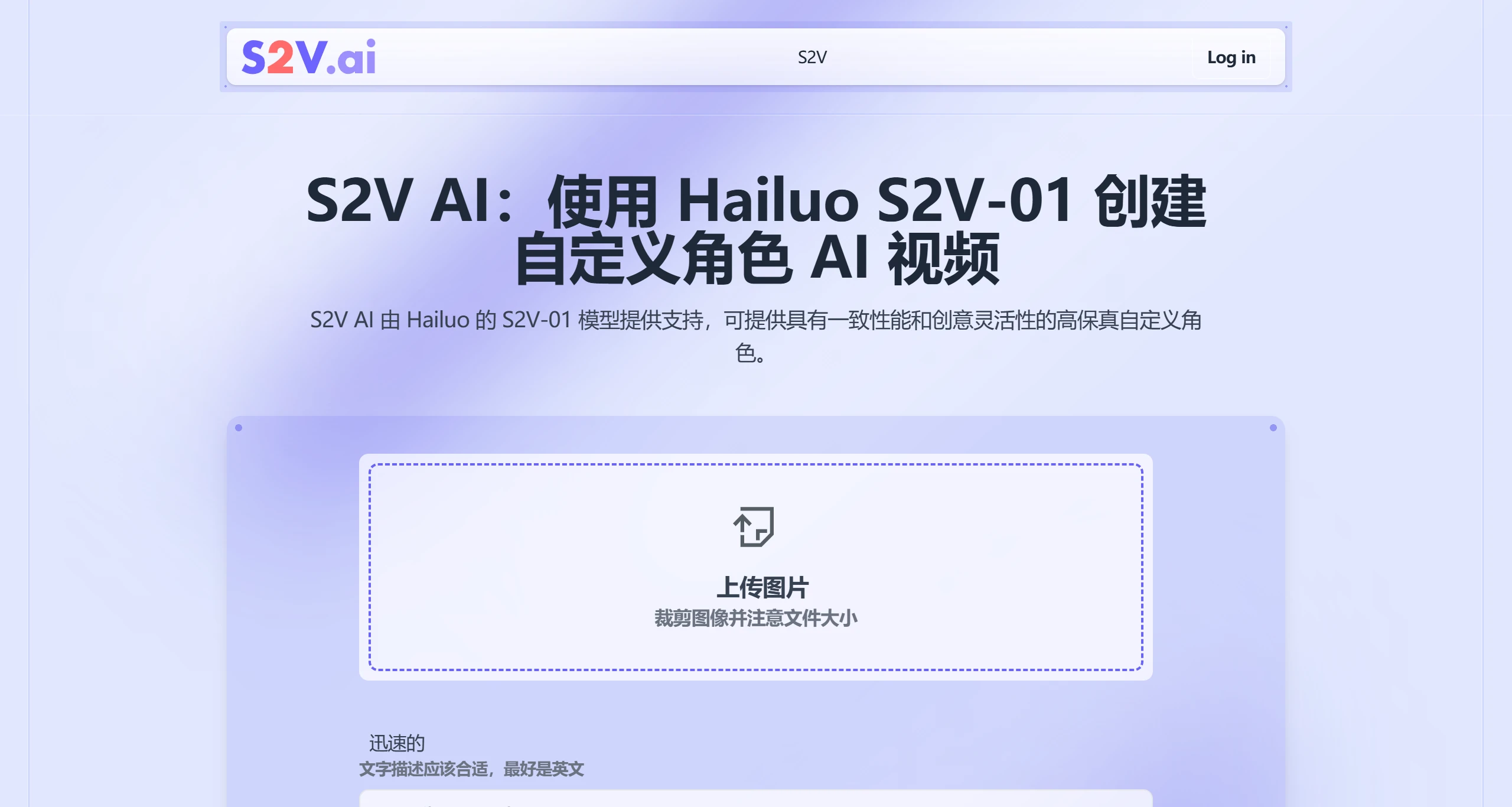
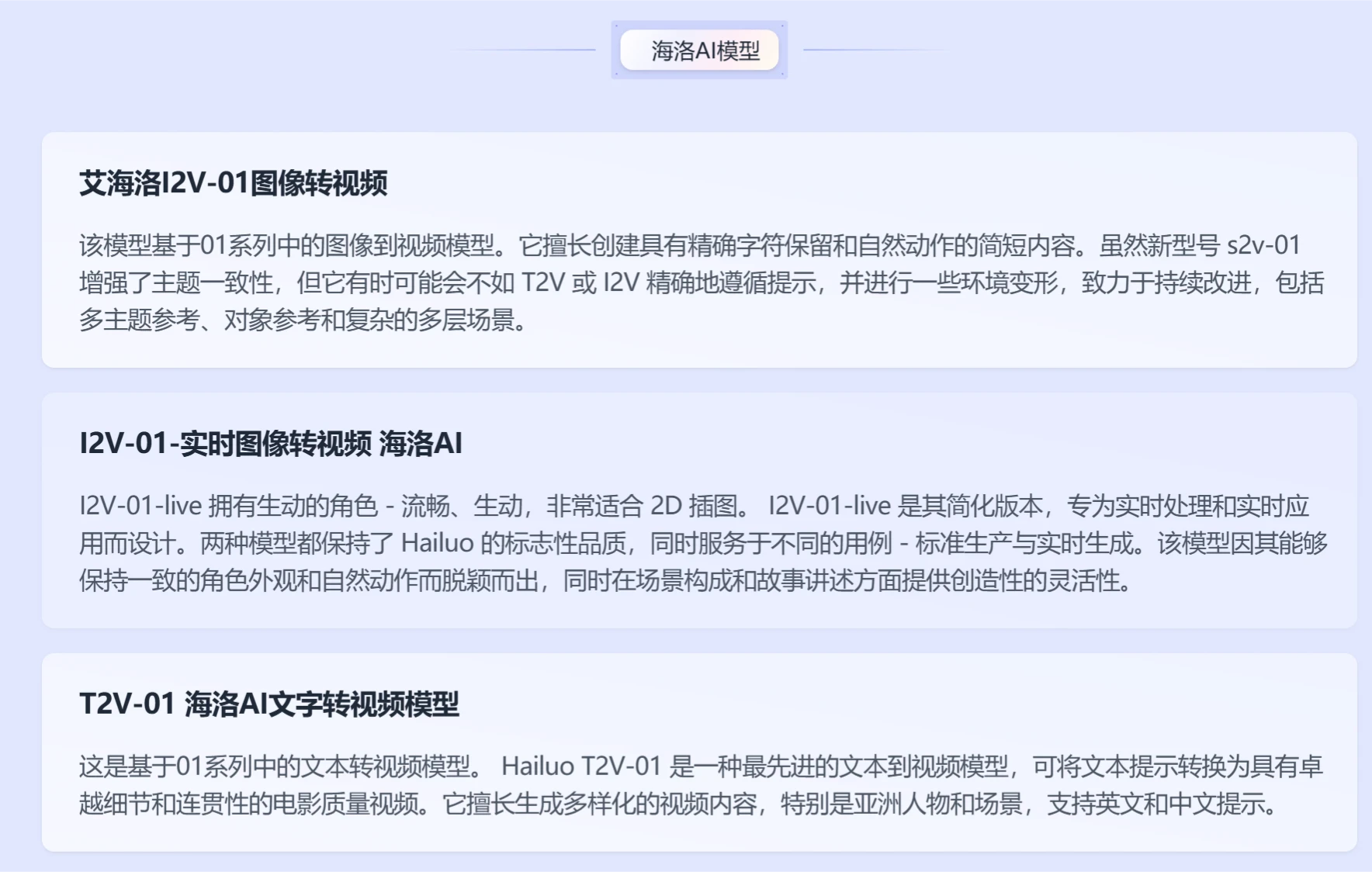

CountAnything
CountAnything是一款结合计算机视觉技术的计数工具,用户可通过拍照或上传图片标注样本,实现物品的自动计数。其功能涵盖工业、农业、物流及建筑等多个应用场景,支持历史数据保存、结果定制等功能,帮助用户提升工作效率与准确性。

