VideoRefer VideoRefer是由浙江大学与阿里达摩院联合开发的视频对象感知与推理系统,基于增强型视频大型语言模型,实现对视频中对象的细粒度理解与分析。其核心包括大规模视频数据集、多功能空间-时间编码器和全面评估基准,支持对象识别、关系分析、推理预测及多模态交互等功能,适用于视频剪辑、教育、安防、机器人控制和电商等多个领域。 AI项目与工具 2025年06月12日 19 点赞 0 评论 631 浏览
VSI VSI-Bench是一种用于评估多模态大型语言模型(MLLMs)视觉空间智能的基准测试工具,包含超过5000个问题-答案对,覆盖多种真实室内场景视频。其任务类型包括配置型任务、测量估计和时空任务,可全面评估模型的空间认知、理解和记忆能力,并提供标准化的测试集用于模型性能对比。 --- AI项目与工具 2025年06月12日 10 点赞 0 评论 587 浏览
MMBench MMBench-Video是一个由多家高校和机构联合开发的长视频多题问答基准测试平台,旨在全面评估大型视觉语言模型(LVLMs)在视频理解方面的能力。平台包含约600个YouTube视频片段,覆盖16个类别,并配备高质量的人工标注问答对。通过自动化评估机制,MMBench-Video能够有效提升评估的精度和效率,为模型优化和学术研究提供重要支持。 AI项目与工具 2025年06月12日 52 点赞 0 评论 577 浏览
LongVU LongVU是一款由Meta AI团队研发的长视频理解工具,其核心在于时空自适应压缩机制,可有效减少视频标记数量并保留关键视觉细节。该工具通过跨模态查询与帧间依赖性分析,实现了对冗余帧的剔除及帧特征的选择性降低,并基于时间依赖性进一步压缩空间标记。LongVU支持高效处理长视频,适用于视频内容分析、搜索索引、生成描述等多种应用场景。 AI项目与工具 2025年06月12日 65 点赞 0 评论 571 浏览
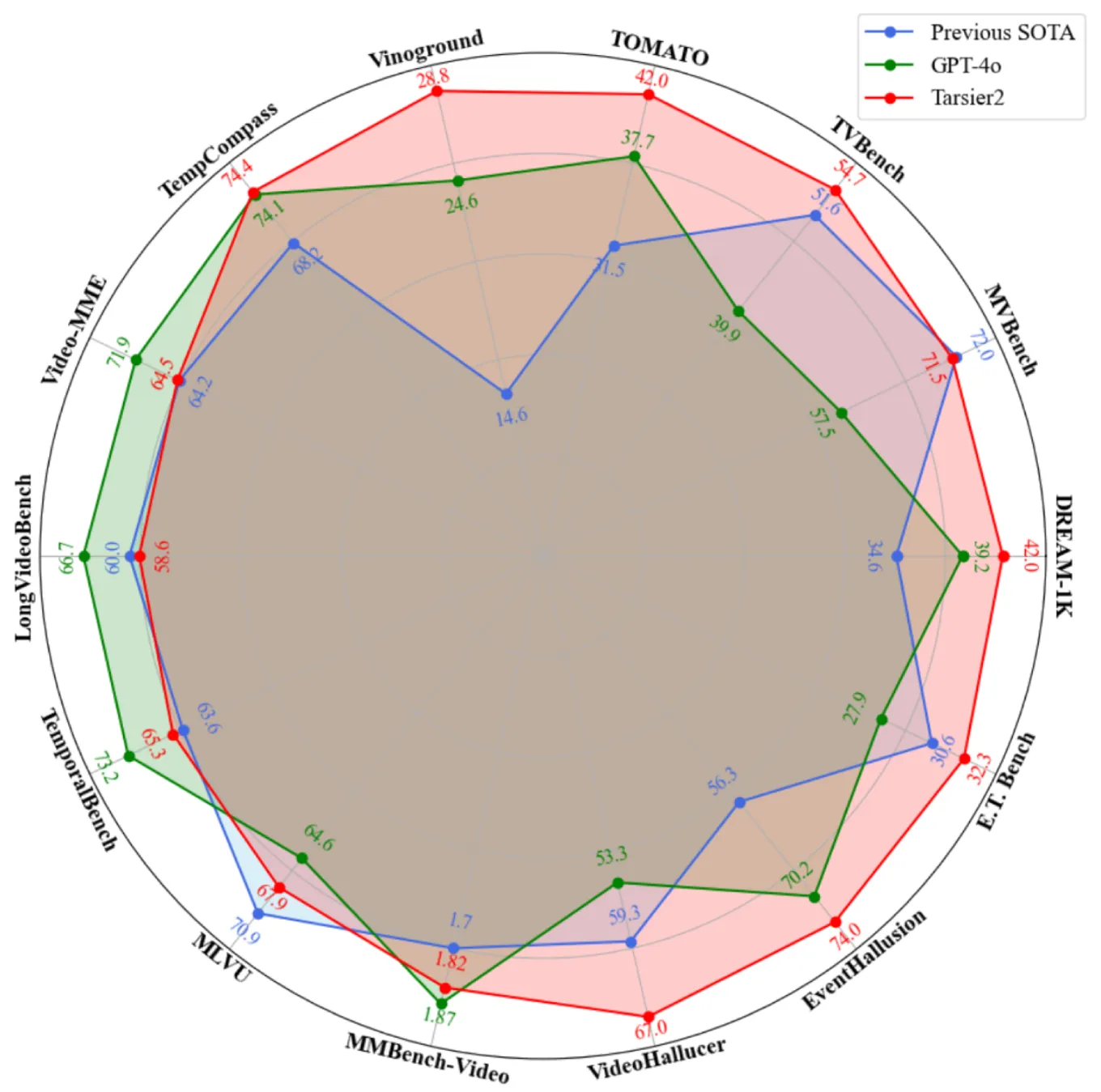
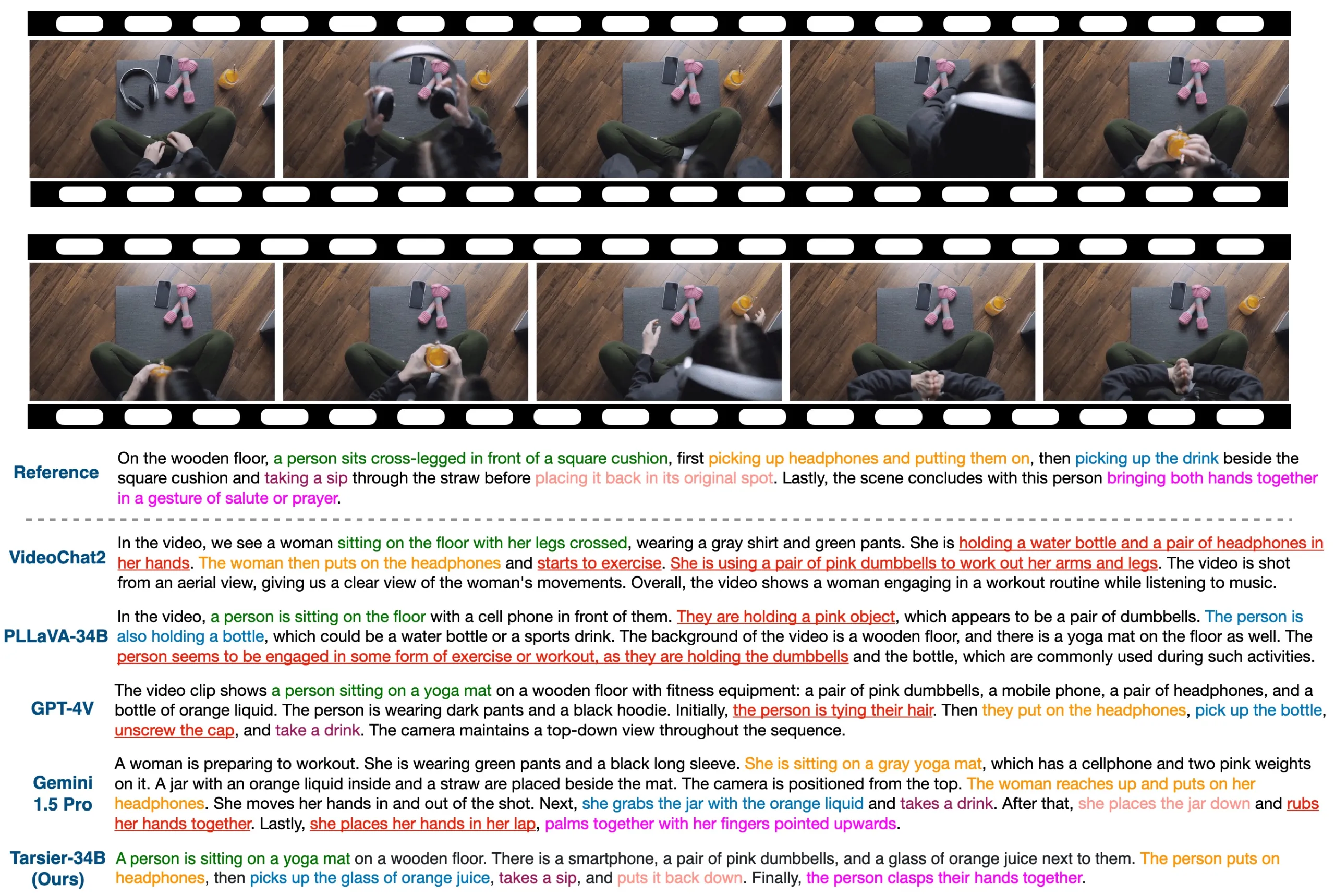
Tarsier 字节跳动推出的一系列大规模视觉语言模型(LVLM),专注于视频理解任务,包括视频描述、问答、视频定位、幻觉测试等功能。 Ai开源项目 2025年06月05日 90 点赞 0 评论 561 浏览
CogSound CogSound是一款基于AI的音效生成工具,能够为无声视频添加与内容匹配的高质量音效,涵盖多种复杂场景。该工具通过先进的音视频特征匹配技术和优化的生成算法,提升了视频的沉浸感和真实感,广泛应用于视频创作、广告制作及影视后期等多个领域。 AI项目与工具 2025年06月12日 12 点赞 0 评论 555 浏览
VideoWorld VideoWorld是由北京交通大学、中国科学技术大学与字节跳动合作开发的深度生成模型,能够通过未标注视频数据学习复杂知识,包括规则、推理和规划能力。其核心技术包括自回归视频生成、潜在动态模型(LDM)和逆动态模型(IDM),支持长期推理和跨环境泛化。该模型在围棋和机器人控制任务中表现优异,且具备向自动驾驶、智能监控等场景扩展的潜力。 AI项目与工具 2025年06月12日 66 点赞 0 评论 550 浏览
mPLUG mPLUG-Owl3是一款由阿里巴巴开发的多模态AI模型,专注于理解和处理多图及长视频内容。该模型具备高推理效率和准确性,采用创新的Hyper Attention模块优化视觉与语言信息的融合。它已在多个基准测试中展现出卓越性能,并且其源代码和资源已公开,可供研究和应用。 AI项目与工具 2025年06月12日 73 点赞 0 评论 519 浏览
Magma Magma是微软研究院开发的多模态AI基础模型,具备理解与执行多模态任务的能力,覆盖数字与物理环境。它融合语言、空间与时间智能,支持从UI导航到机器人操作的复杂任务。基于大规模视觉-语言和动作数据预训练,Magma在零样本和微调设置下表现优异,适用于网页操作、机器人控制、视频理解及智能助手等多个领域。 AI项目与工具 2025年06月12日 100 点赞 0 评论 513 浏览
Video Video-LLaVA2是一款由北京大学ChatLaw课题组开发的开源多模态智能理解系统。该系统通过时空卷积(STC)连接器和音频分支,显著提升了视频和音频的理解能力。其主要功能包括视频理解、音频理解、多模态交互、视频问答和视频字幕生成。时空建模和双分支框架是其核心技术原理。Video-LLaVA2广泛应用于视频内容分析、视频字幕生成、视频问答系统、视频搜索和检索、视频监控分析及自动驾驶等领域。 AI项目与工具 2025年06月12日 50 点赞 0 评论 507 浏览