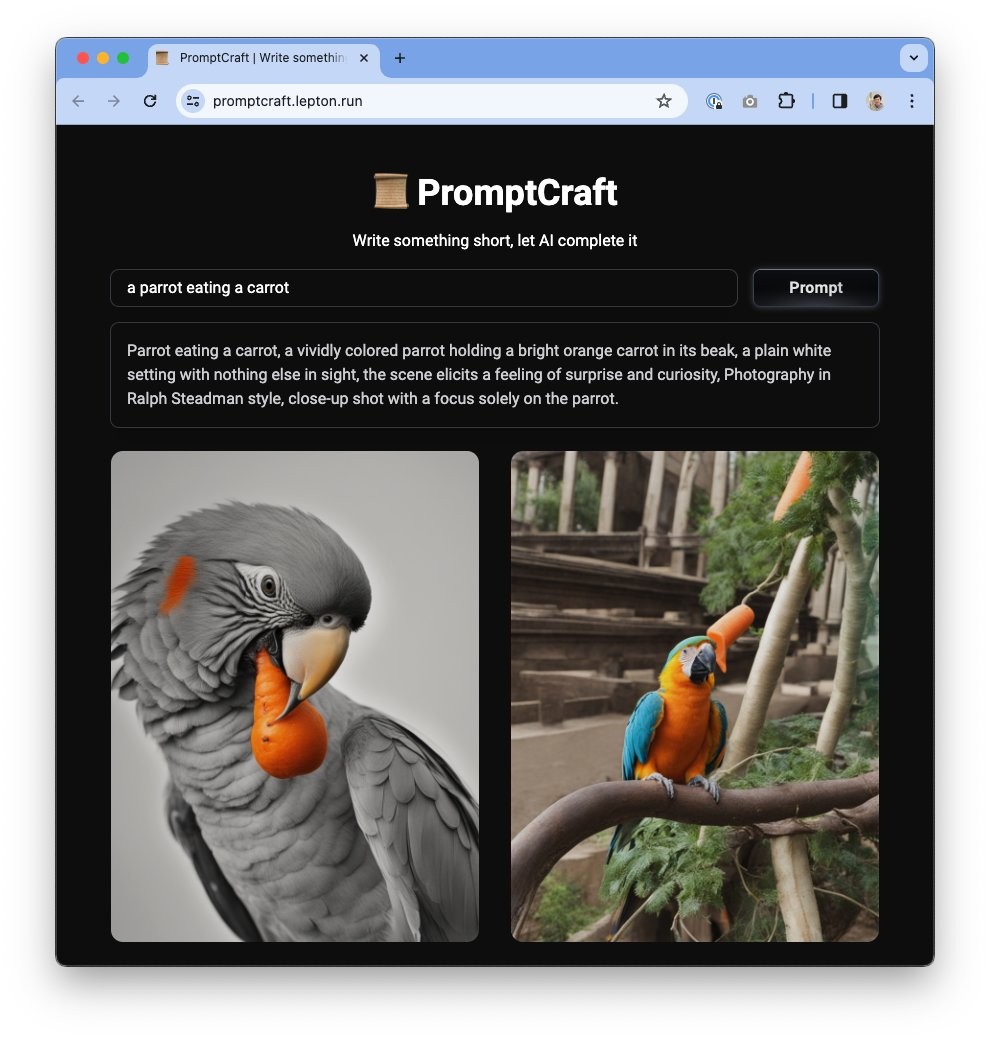
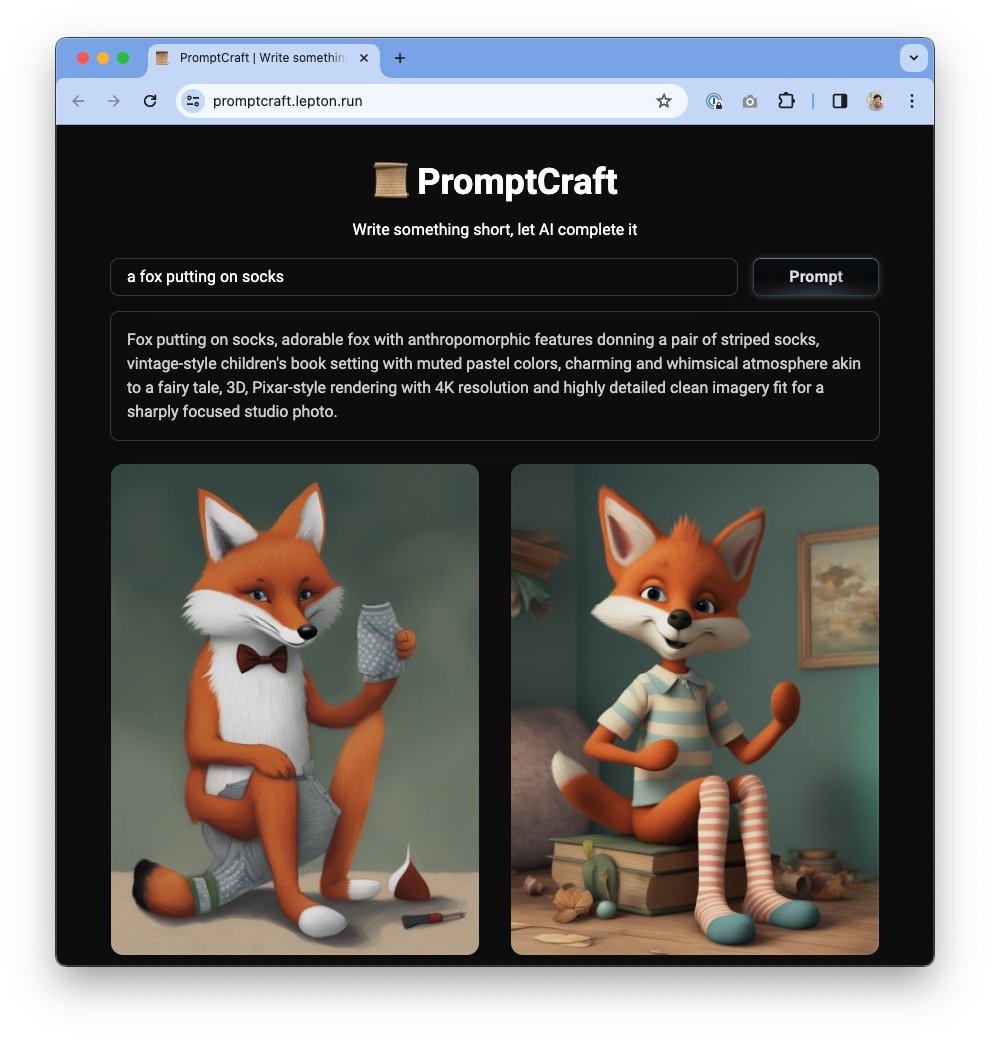
千影QianYing 巨人网络发布的有声游戏生成大模型,主要包括游戏视频生成大模型YingGame和视频配音大模型YingSound。 Ai平台模型 2025年06月05日 58 点赞 0 评论 777 浏览
腾讯混元3D 全称为Hunyuan3D-1.0,是腾讯推出的一款同时支持文生和图生的3D开源模型,解决现有3D生成模型在生成速度和泛化能力的不足。 Ai开源项目 2025年06月05日 59 点赞 0 评论 669 浏览
Mirageml Mirageml是一家使用人工智能 (AI) 帮助创意人员设计 3D 资源和场景的公司,Mirage 的 AI 可以根据自然语言提示或草图生成逼真且高质量的 3D 模型。 3D&游戏 2025年06月05日 39 点赞 0 评论 773 浏览
PartCrafter PartCrafter是一款先进的3D生成模型,能够从单张RGB图像中生成多个语义明确且几何形态各异的3D网格。通过组合潜在空间表示每个3D部件,并利用层次化注意力机制确保全局一致性。该模型基于预训练的3D网格扩散变换器(DiT),支持多部件联合生成、端到端生成和部件级编辑,适用于游戏开发、建筑设计、影视制作等多个领域。 AI项目与工具 2025年06月11日 66 点赞 0 评论 771 浏览
混元图像2.0 混元图像2.0是腾讯开发的AI图像生成工具,支持文本、语音、草图等多种输入方式,具备实时生成能力。其采用单双流DiT架构和多模态大语言模型,生成图像写实性强、细节丰富,且响应速度快,适用于创意设计、广告营销、教育、游戏等多个领域。用户可通过网页端直接操作,实现高效的图像创作体验。 AI项目与工具 2025年06月11日 41 点赞 0 评论 487 浏览
万相首尾帧模型 万相首尾帧模型(Wan2.1-FLF2V-14B)是一款开源视频生成工具,基于DiT架构和交叉注意力机制,可根据用户提供的首帧和尾帧图像生成高质量、流畅的过渡视频。支持多种风格和特效,适用于创意视频制作、影视特效、广告营销等多个场景。模型具备细节复刻、动作自然、指令控制等功能,且提供GitHub和HuggingFace开源资源供用户使用。 AI项目与工具 2025年06月11日 100 点赞 0 评论 724 浏览
WorldScore WorldScore是由斯坦福大学推出的统一世界生成模型评估基准,支持3D、4D、图像到视频(I2V)和文本到视频(T2V)等多种模态。它从可控性、质量和动态性三个维度进行评估,涵盖3000个测试样本,包括静态与动态、室内与室外、逼真与风格化等多种场景。WorldScore具备多场景生成、长序列支持、图像条件生成、多风格适配等功能,适用于图像到视频、图像到3D生成以及自动驾驶场景模拟等应用,为研究 AI项目与工具 2025年06月12日 87 点赞 0 评论 788 浏览
Vidu Q1 Vidu Q1是清华大学朱军教授团队研发的高可控视频生成模型,支持1080p高清视频生成,具备精准音效控制、多主体一致性调节、局部超分重建等功能。在多项国际评测中表现优异,包括VBench和SuperCLUE榜单均获第一。模型基于扩散模型与U-ViT架构,融合文本、图像和视频信息,适用于影视制作、广告宣传及动画创作等领域。 AI项目与工具 2025年06月12日 96 点赞 0 评论 573 浏览
TripoSF TripoSF是由VAST推出的新型3D基础模型,采用SparseFlex表示方法和稀疏体素结构,显著降低内存占用并提升高分辨率建模能力。其“视锥体感知的分区体素训练”策略优化了训练效率,使模型在细节捕捉、拓扑结构支持和实时渲染方面表现突出。实验数据显示,TripoSF在Chamfer Distance和F-score等关键指标上分别降低82%和提升88%。适用于视觉特效、游戏开发、具身智能及产品 AI项目与工具 2025年06月12日 71 点赞 0 评论 788 浏览