DiffuEraser DiffuEraser是一款基于稳定扩散模型的视频修复工具,具备未知像素生成、已知像素传播、时间一致性维护等功能。通过集成运动模块和优化网络架构,它能有效提升视频修复质量,减少噪声和幻觉。适用于影视后期制作、老电影修复、监控视频增强等多个领域,支持高精度和高连贯性的视频内容修复与增强。 AI项目与工具 2025年06月12日 98 点赞 0 评论 772 浏览
ChatLaw ChatLaw是一款针对中文法律领域的大型语言模型,它通过定制化的设计和智能分析功能,为法律专业人士提供了一个强大的工具。 Ai平台模型 1970年01月01日 0 点赞 0 评论 772 浏览
Tensor.Art Tensor.Art 是一款基于 AI 技术的图像生成平台,支持用户通过文字描述生成高质量图像。平台提供多种模型类型,支持模型共享、在线运行及训练,并拥有 ControlNet、图像到图像等功能。Tensor.Art 构建了活跃的创作者社区,适用于艺术创作、广告设计、教育等多个领域,为用户提供便捷高效的图像生成解决方案。 AI项目与工具 2025年06月12日 23 点赞 0 评论 772 浏览
Google AI Edge Gallery Google AI Edge Gallery 是谷歌推出的实验性应用,支持在 Android 设备上本地运行机器学习和生成式人工智能模型,无需联网。用户可切换不同模型,进行图像问答、文本生成、多轮对话等操作,并实时查看性能指标。应用支持自带模型测试,提供丰富的开发者资源,助力探索设备端 AI 的强大功能。 AI项目与工具 2025年06月11日 75 点赞 0 评论 772 浏览
TrackVLA TrackVLA是银河通用推出的端到端导航大模型,具备纯视觉环境感知、语言指令驱动、自主推理和零样本泛化能力。它能在复杂环境中自主导航、灵活避障,并根据自然语言指令识别和跟踪目标对象。无需提前建图,适用于多种场景,如陪伴服务、安防巡逻、物流配送等,为具身智能商业化提供支撑,推动机器人走向日常生活。 AI项目与工具 2025年06月11日 79 点赞 0 评论 772 浏览
In In-Context LoRA是一种基于扩散变换器(DiTs)的图像生成框架,通过微调少量数据实现多样化图像生成任务。它无需修改原始模型结构,减少了对大规模标注数据的依赖,同时保持了高质量的生成效果。该工具支持多任务图像生成、上下文学习能力、任务无关性以及条件图像生成等功能,适用于故事板生成、字体设计、家居装饰等多个领域。 AI项目与工具 2025年06月12日 35 点赞 0 评论 773 浏览
Ultravox Ultravox 是一种多模态大型语言模型(LLM),能够直接处理文本和语音输入,无需额外的语音识别步骤。其核心技术包括多模态投影器,用于将音频数据转换为高维空间表示,显著提升语音理解和处理效率。该模型支持实时语音对话、多语言扩展及领域特定知识的学习,适用于智能客服、虚拟助手、语言学习、实时翻译及教育等领域。 AI项目与工具 2025年06月12日 51 点赞 0 评论 773 浏览
AgentSquare AgentSquare是一款由清华大学团队研发的模块化设计工具,专注于在大型语言模型代理的设计空间内实现高效搜索。其核心功能包括模块化设计、模块重组与进化、性能预测及自动化搜索等,通过标准化接口支持模块间无缝集成,广泛应用于客户服务、个人助理、教育、医疗及金融等多个领域,旨在提升智能体性能并降低推理成本。 AI项目与工具 2025年06月12日 39 点赞 0 评论 773 浏览
Mirageml Mirageml是一家使用人工智能 (AI) 帮助创意人员设计 3D 资源和场景的公司,Mirage 的 AI 可以根据自然语言提示或草图生成逼真且高质量的 3D 模型。 3D&游戏 2025年06月05日 39 点赞 0 评论 774 浏览
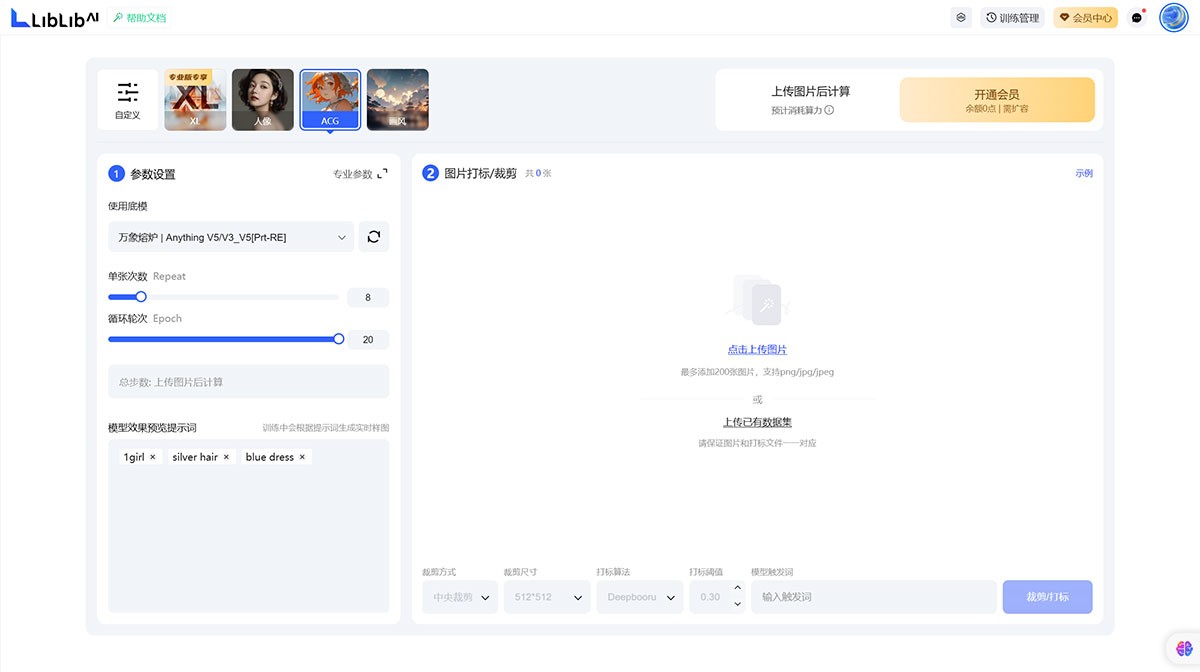
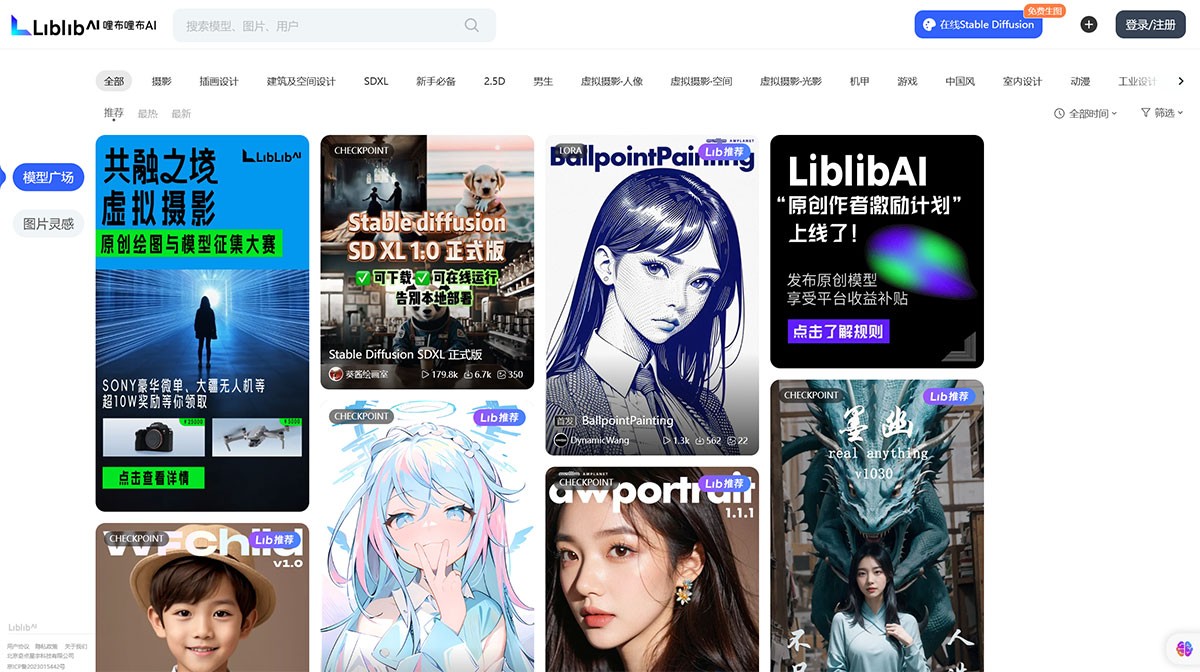
哩布哩布AI liblibai哩布哩布AI,原创AI模型分享社区,这里有最新、热门的模型素材,10万+模型免费下载。欢迎每一位创作者加入,分享你的作品。与中国原创模型作者交流,共同探索AI绘画。 Ai绘画生成 2025年06月05日 31 点赞 0 评论 774 浏览