Minister AI Minister AI是一款免费使用的AI绘图工具,登录即用的在线Stable Diffusion,支持海量模型上传下载。 Ai绘画生成 2025年06月05日 28 点赞 0 评论 742 浏览
通古大模型 通古大模型是由华南理工大学研发的古籍文言文处理AI工具,基于百川2-7B-Base进行增量预训练,结合24.1亿古籍语料和400万对话数据,采用RAT和RAG技术提升古籍处理效果。支持古文句读、文白翻译、诗词创作、古籍赏析、检索问答及辅助整理等功能,广泛应用于古籍数字化、教育、文化传承与学术研究等领域。 AI项目与工具 2025年06月12日 61 点赞 0 评论 742 浏览
Gemini 2.0 Flash Gemini 2.0 Flash是Google推出的多模态AI模型,支持文本与图像生成及对话式编辑,能根据自然语言生成连贯图像,并保持上下文一致性。其在长文本渲染方面表现优异,适用于广告、社交媒体、教育等领域。开发者可通过Google AI Studio或Gemini API进行测试和集成,广泛应用于创意插图、互动故事、设计辅助等场景。 AI项目与工具 2025年06月12日 18 点赞 0 评论 743 浏览
ChatGPT Canvas Canvas是一款由OpenAI开发的AI协作工具,集成了写作与编程功能。它支持实时运行Python代码,提供代码审查、注释、错误修复及多语言代码转换等辅助功能。其上下文感知功能可实时优化文章结构,同时支持自定义GPT模型。Canvas在写作和编程领域均表现出色,适用于个人和团队协作。 AI项目与工具 2025年06月12日 65 点赞 0 评论 743 浏览
Command A Command A 是 Cohere 推出的企业级生成式 AI 模型,具备高性能和低硬件需求,支持 256k 上下文长度及 23 种语言。集成 RAG 技术,提升信息准确性。适用于文档分析、多语言处理、智能客服和数据分析等场景,适合企业部署使用。 AI项目与工具 2025年06月12日 48 点赞 0 评论 744 浏览
K2 地球科学的开源大预言模型,首先在收集和清理过的地球科学文献(包括地球科学开放存取论文和维基百科页面)上对 LLaMA 进行进一步预训练,然后使用知识密集型指令调整数据(GeoSig... Ai平台模型 1970年01月01日 0 点赞 0 评论 744 浏览
InftyThink InftyThink是一种创新的大模型推理范式,通过分段迭代和阶段性总结的方式,突破传统模型在长推理任务中的上下文窗口限制,显著降低计算复杂度并提升推理性能。它适用于数学问题求解、逻辑推理、代码生成、智能辅导及药物研发等多个领域,具备良好的工程可落地性和广泛的适用性。 AI项目与工具 2025年06月12日 10 点赞 0 评论 744 浏览
Ministral 3B/8B Ministral 3B 和 8B 是由 Mistral AI 开发的两款轻量级 AI 模型,专为设备端和边缘计算设计。它们具备强大的知识处理能力和高效的上下文管理能力,支持长达 128k 的上下文长度,并通过独特的交错滑动窗口注意力机制提升了推理速度。这些模型适用于设备端翻译、本地数据分析、智能助手及自主机器人等领域,同时支持无损量化和私有部署。 AI项目与工具 2025年06月12日 63 点赞 0 评论 744 浏览
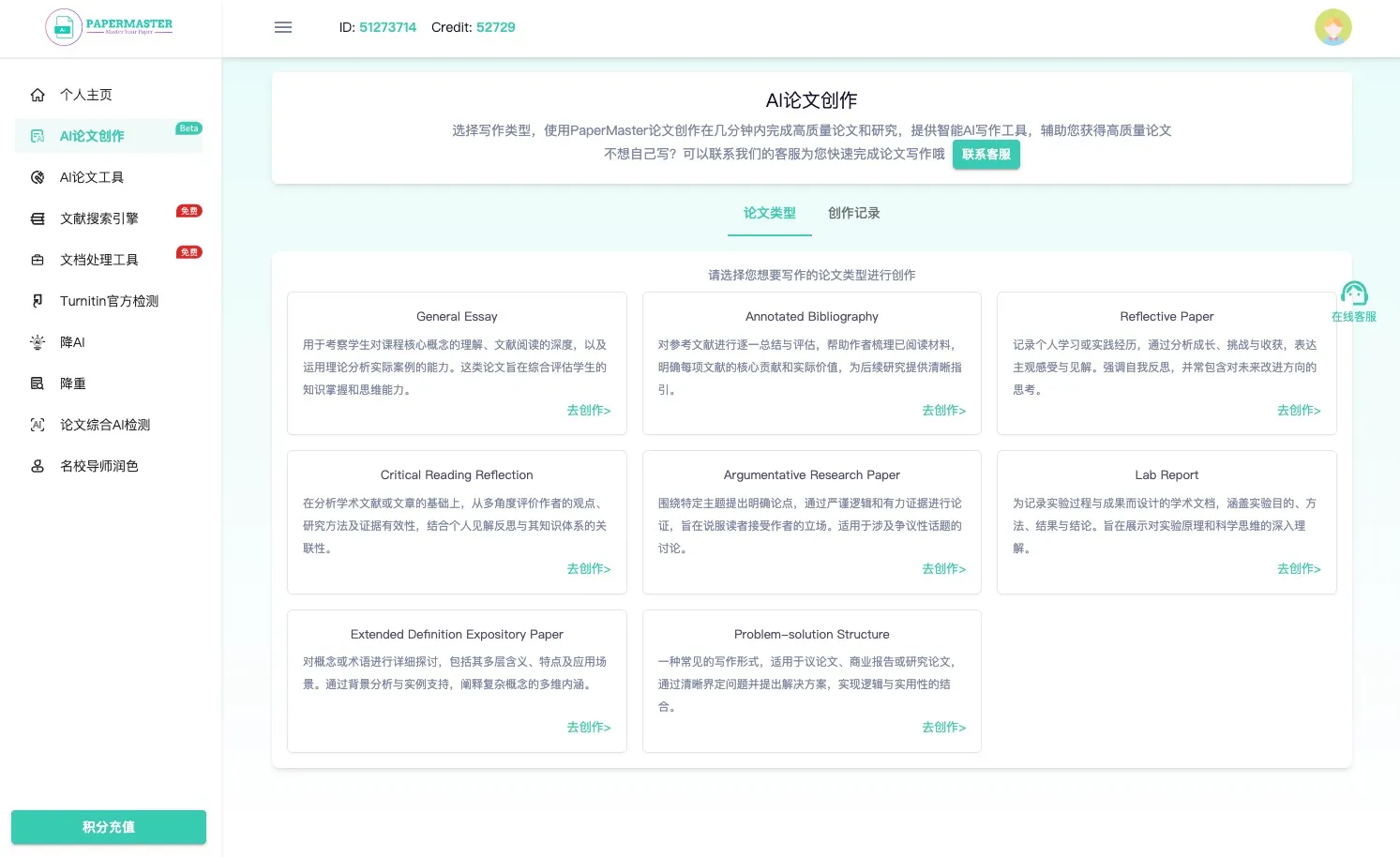
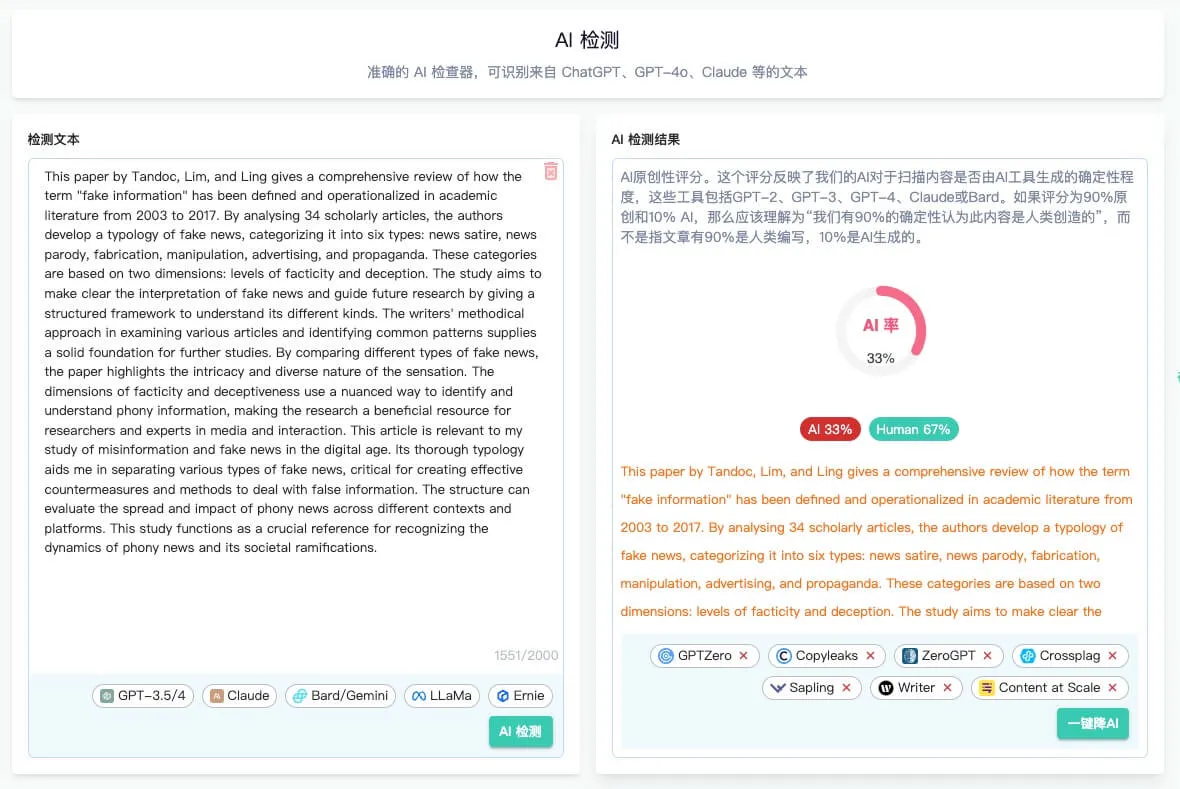
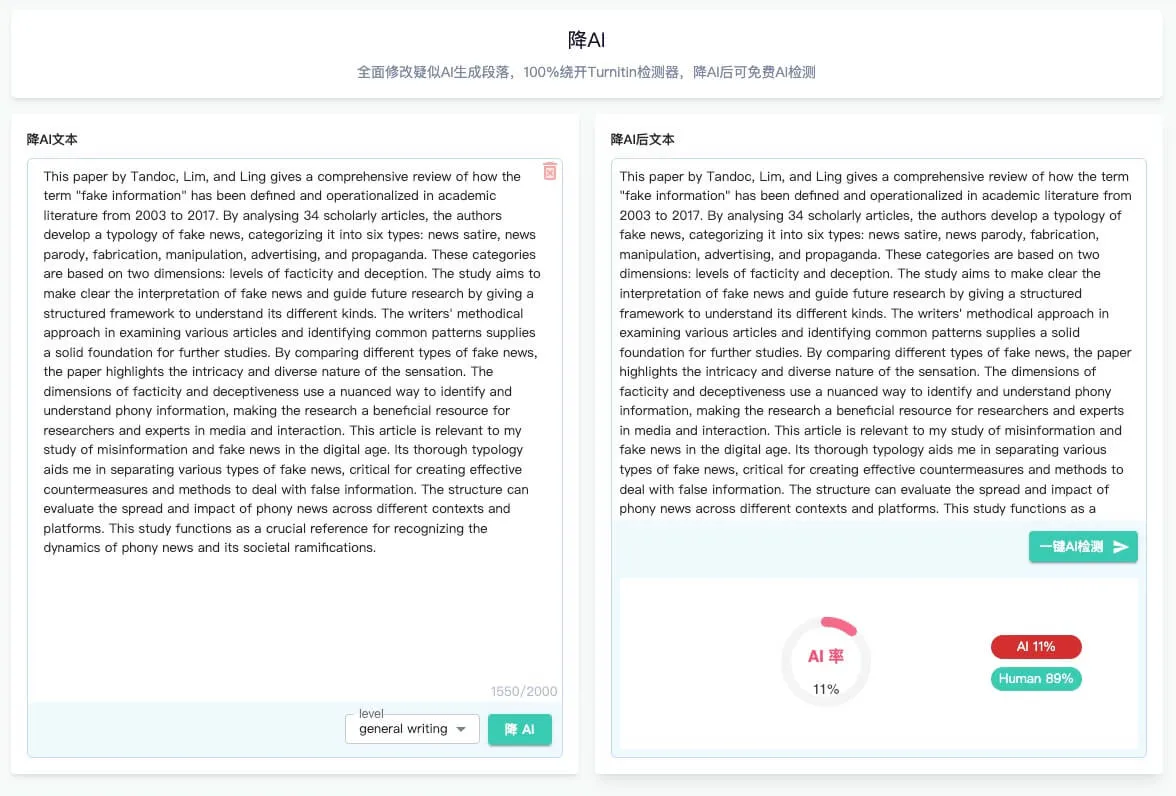
PaperMaster AI 安全、专业、权威的全体系论文解决方案,PaperMaster通过AI快速生成高质量的学术论文和研究报告,并提供论文创作、查重检测和降重服务等功能。 教育学习 2025年06月05日 93 点赞 0 评论 745 浏览
MaskGCT MaskGCT是一款基于掩码生成模型与语音表征解耦编码技术的语音合成大模型,由趣丸科技与香港中文大学(深圳)联合开发。其主要功能包括声音克隆、跨语种语音合成、语音控制及高质量语音数据集支持。该模型在多个TTS基准数据集上表现优异,可快速精准地克隆音色并灵活调整语音属性,适用于多种语言,已开源并面向全球用户开放。 AI项目与工具 2025年06月12日 35 点赞 0 评论 746 浏览