模型




Awesome Chinese LLM
整理了开源的中文大语言模型(LLM),主要关注规模较小、可私有化部署且训练成本较低的模型,目前已收录了100多个相关资源。
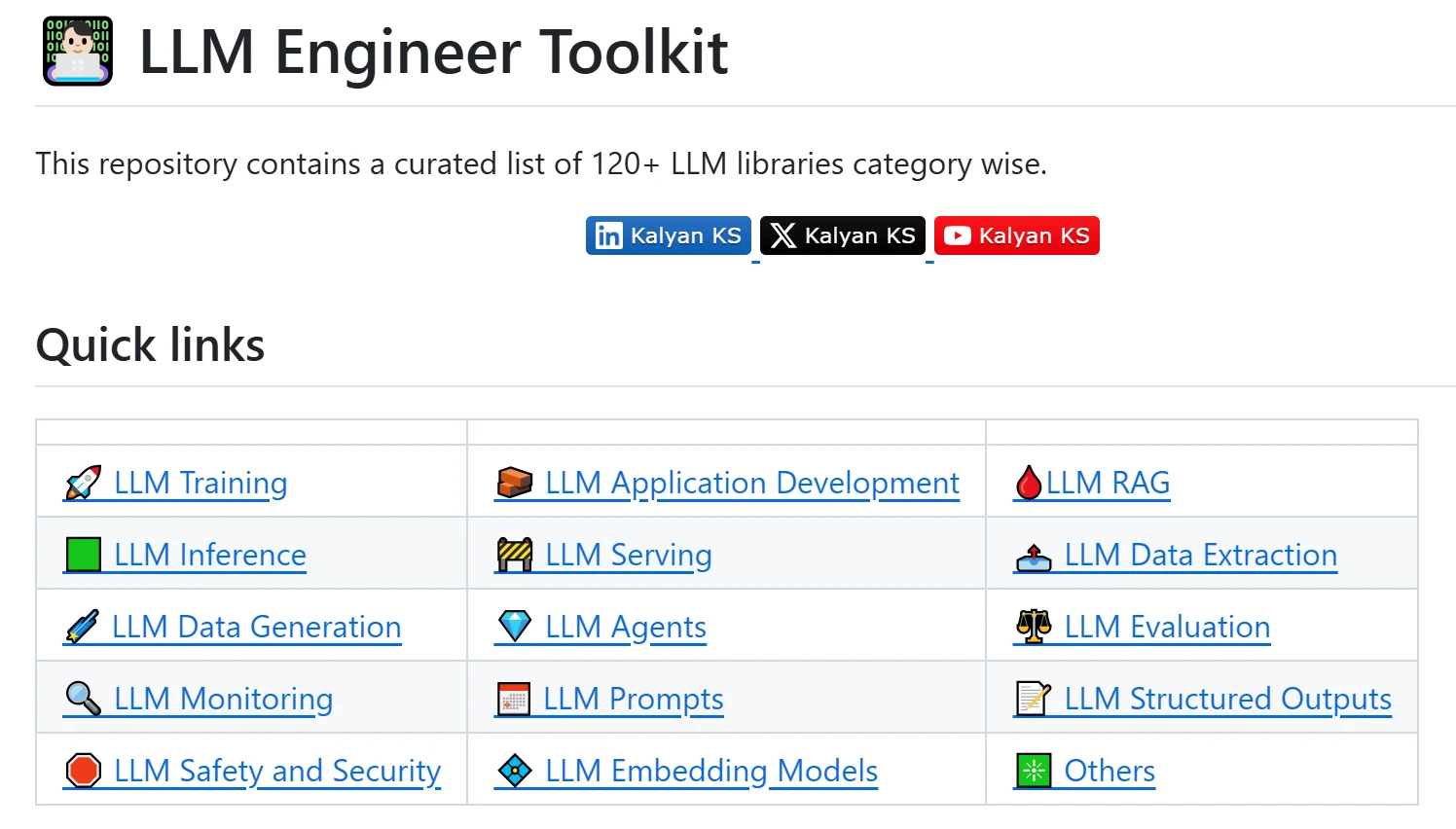
Awesome MCP ZH
一个专为中文用户打造的 MCP资源合集! 包括有 MCP 的基础介绍、玩法、客户端、服务器和社区资源,帮你快速上手这个 AI 界的“万能插头”。

Awesome GPT
一个精选的GPT-4o生成图片集锦,收集了OpenAI 最新多模态模型 GPT‑4o 生成的精彩案例,展示其强大的文本‑图像理解与创作能力。