扩散模型

VideoDrafter
一个高质量视频生成的开放式扩散模型,相比之前的生成视频模型,VideoDrafter最大的特点是能在主体不变的基础上,一次性生成多个场景的视频。



LucidDreamer
LucidDreamer,可以从单个图像的单个文本提示中生成可导航的3D场景。 单击并拖动(导航)/移动和滚动(缩放)以感受3D。





PlayDiffusion
PlayDiffusion是Play AI推出的音频编辑模型,基于扩散模型技术实现音频的精细编辑和修复。它将音频编码为离散标记序列,通过掩码处理和去噪生成高质量音频,保持语音连贯性和自然性。支持局部编辑、高效文本到语音合成、动态语音修改等功能,具有非自回归特性,提升生成速度与质量。适用于配音纠错、播客剪辑、实时语音互动等场景。

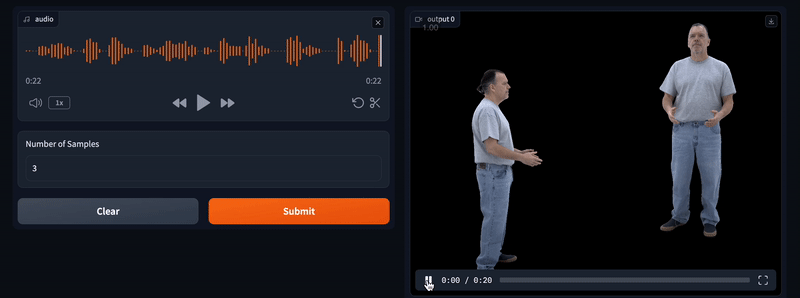
HunyuanPortrait
HunyuanPortrait是由腾讯Hunyuan团队联合多所高校推出的基于扩散模型的肖像动画生成工具。它能够根据一张肖像图片和视频片段,生成高度可控且逼真的动画,保持身份一致性并捕捉细微表情变化。该工具在时间一致性和泛化能力方面表现优异,适用于虚拟现实、游戏、人机交互等多个领域。
