多语言支持


Herodot AI
Herodot AI是一款利用AI技术打造的旅行助手,能够提供个性化的沉浸式旅行体验。它支持多语言叙述和角色设定,允许用户通过拍照识别景点信息,并借助地图功能深入了解各地的文化和历史背景。无论是个人旅行、家庭出游还是教育旅行,Herodot AI都能满足用户的学习和探索需求,同时为商务旅行者提供实用的文化背景参考。

VoiceCanvas
VoiceCanvas 是一款开源的多语言语音合成平台,基于 AI 技术提供高质量文字转语音服务,支持超过 50 种语言。用户可通过上传简短音频实现个性化声音克隆,并集成多种语音服务以保障输出质量。平台适用于内容创作、教育、企业及个人等多种场景,提升语音内容制作效率。





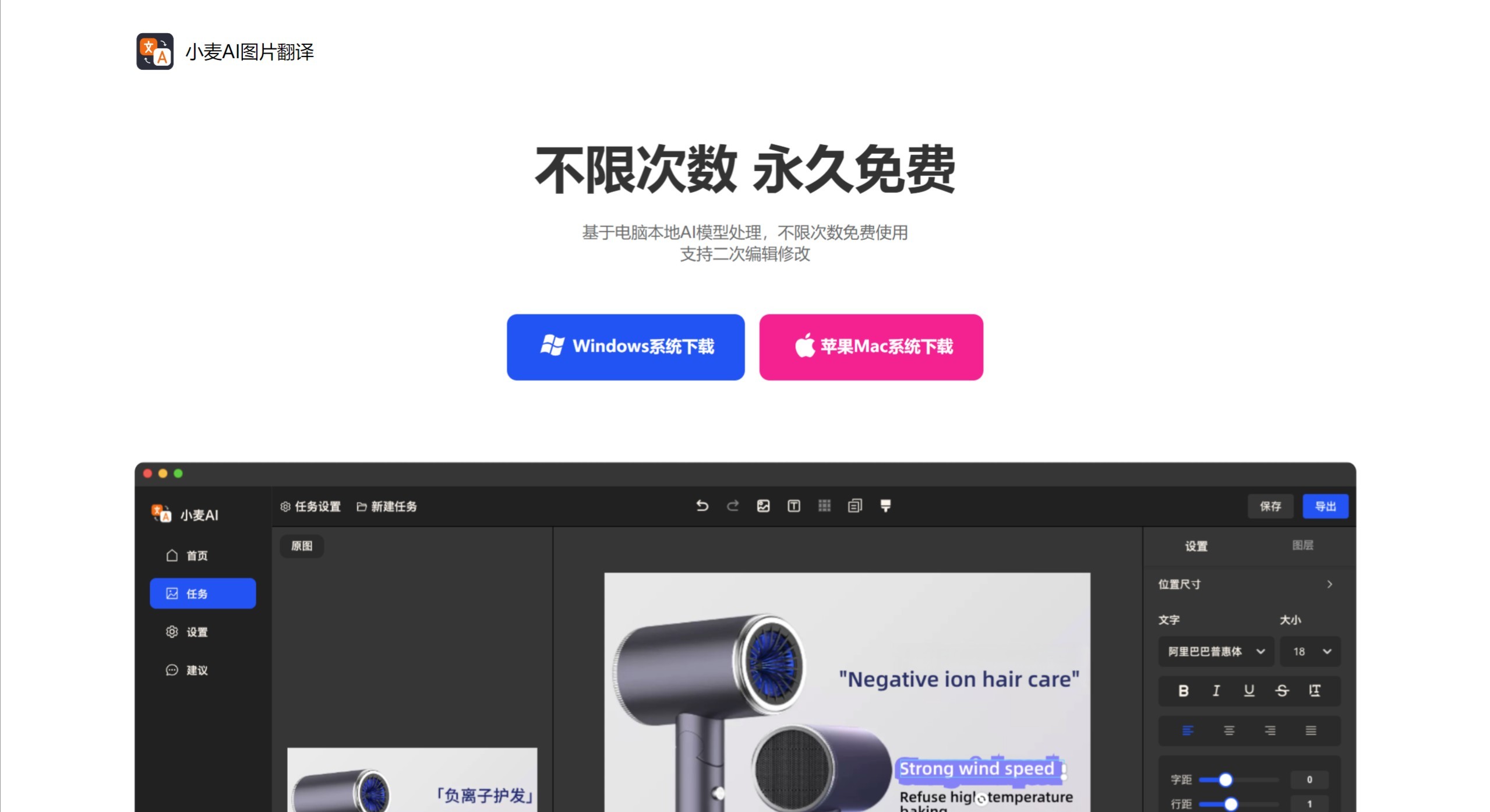
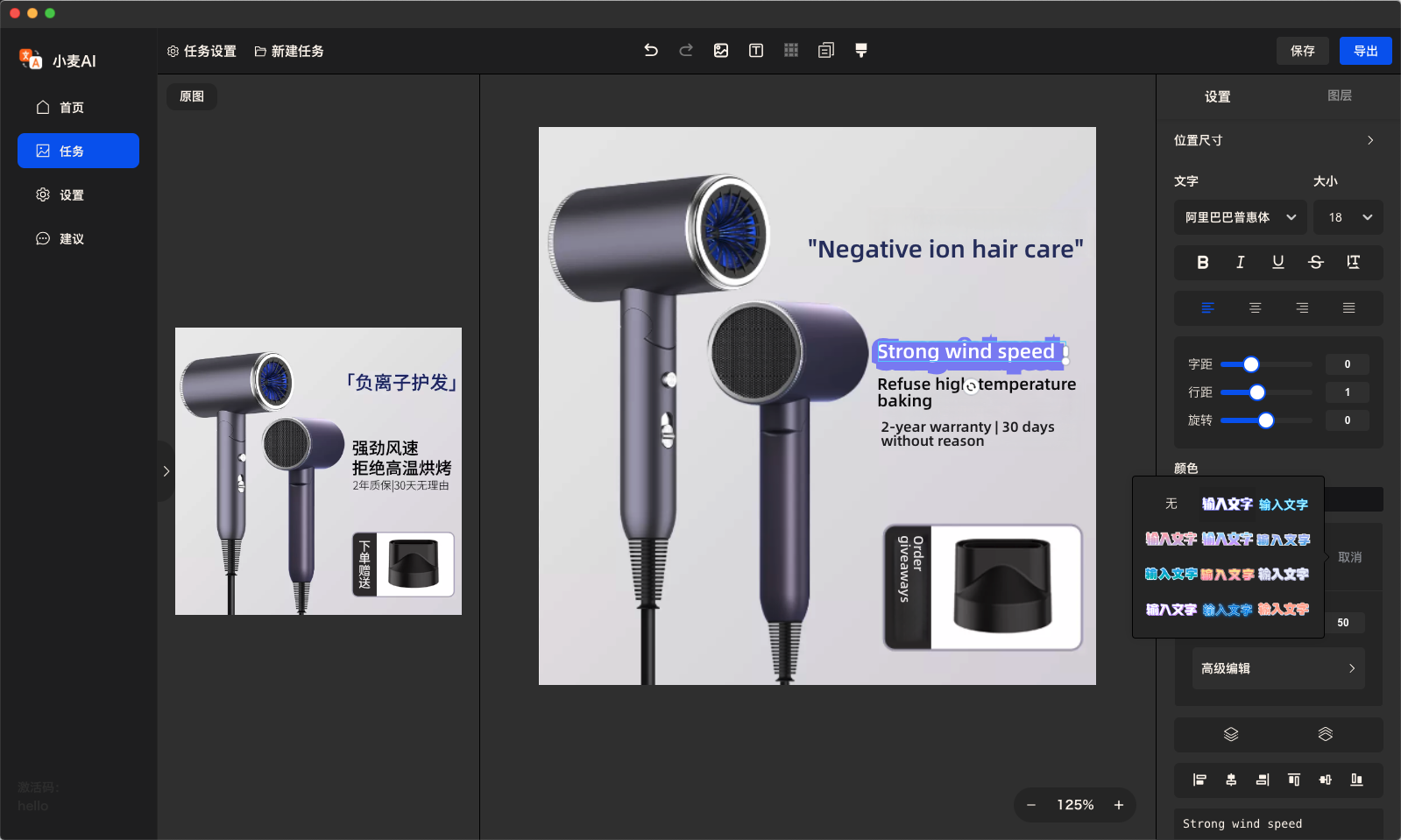

RTranslator
RTranslator是一款基于AI技术的开源、免费离线翻译应用,专为Android设备设计。它支持对话模式、对讲机模式及文本翻译功能,能够实现高质量的多语言实时翻译。RTranslator采用Meta的NLLB翻译模型和OpenAI的Whisper语音识别技术,支持多种语言,完全离线运行,保障用户隐私安全。
