Voyage Multimodal Voyage Multimodal-3 是一款多模态嵌入模型,能够处理文本、图像以及它们的混合数据,无需复杂文档解析即可提取关键视觉特征。它在多模态检索任务中的准确率显著高于现有最佳模型,支持语义搜索和文档理解,适用于法律、金融、医疗等多个领域的复杂文档检索任务。 AI项目与工具 2025年06月12日 27 点赞 0 评论 657 浏览
跃问 一款免费AI聊天机器人,个人效率助手,跃问支持多模态能力,能够理解图片物体、阅读总结文档信息和解析网页内容,支持连续的多轮对话等。 AI写作对话 2025年06月05日 47 点赞 0 评论 658 浏览
FakeShield FakeShield是一款由北京大学研发的多模态大型语言模型框架,主要用于检测和定位图像篡改。它通过结合视觉与文本信息,生成篡改区域掩码并提供详细的判断依据。其核心模块包括领域标签引导的检测模块和多模态定位模块,支持多种篡改技术的分析,具有较高的准确性与可解释性。FakeShield广泛应用于社交媒体内容审核、法律取证、新闻媒体真实性验证以及版权保护等领域。 AI项目与工具 2025年06月12日 41 点赞 0 评论 659 浏览
AI推理模型有哪些?13个支持深度思考的推理模型 本文介绍了13款支持深度思考的AI推理模型,涵盖数学、代码、自然语言推理等多个领域。这些模型通过强化学习和大数据分析,能够高效处理复杂问题,提供精准的决策支持。部分模型具备多模态处理能力、透明推理过程及开源特性,适用于不同应用场景,如教育、医疗和科研等。 AI项目与工具 2025年06月11日 88 点赞 0 评论 659 浏览
HourVideo HourVideo是一项由斯坦福大学研发的长视频理解基准数据集,包含500个第一人称视角视频,涵盖77种日常活动,支持多模态模型的评估。数据集通过总结、感知、视觉推理和导航等任务,测试模型对长时间视频内容的信息识别与综合能力,推动长视频理解技术的发展。其高质量的问题生成流程和多阶段优化机制,使其成为学术研究的重要工具。 AI项目与工具 2025年06月12日 77 点赞 0 评论 659 浏览
CAR CAR(Certainty-based Adaptive Reasoning)是字节跳动联合复旦大学推出的自适应推理框架,旨在提升大型语言模型(LLM)和多模态大型语言模型(MLLM)的推理效率与准确性。该框架通过动态切换短答案和长形式推理,根据模型对答案的置信度(PPL)决定是否进行详细推理,从而在保证准确性的同时节省计算资源。CAR适用于视觉问答(VQA)、关键信息提取(KIE)等任务,在数学 AI项目与工具 2025年06月11日 73 点赞 0 评论 660 浏览
Motion Anything Motion Anything 是一款由多所高校与企业联合研发的多模态运动生成框架,可基于文本、音乐或两者结合生成高质量人类运动。其核心在于基于注意力的掩码建模和跨模态对齐技术,实现对运动序列的精细控制与动态优先级调整。该工具支持影视动画、VR/AR、游戏开发、人机交互及教育等多个应用场景,并配套提供 Text-Music-Dance (TMD) 数据集,推动多模态运动生成技术的发展。 AI项目与工具 2025年06月12日 23 点赞 0 评论 660 浏览
冒泡鸭AI 一个基于多模态大模型技术的AI聊天机器人和AI智能体平台,冒泡鸭AI内部载有众多由大模型技术驱动的智能对话实体,这些"智能体"不仅致力于为用户解答疑惑、激发创意,还能深度聊天,旨在与用户建立情感纽带。 AI写作对话 2025年06月05日 99 点赞 0 评论 660 浏览
豆包大模型1.5 豆包大模型1.5是字节跳动推出的高性能AI模型,采用大规模稀疏MoE架构,具备卓越的综合性能和多模态能力。支持文本、语音、图像等多种输入输出方式,适用于智能辅导、情感分析、文本与视频生成等场景。模型训练数据完全自主,性能优于GPT-4o和Claude 3.5 Sonnet等主流模型,且具备成本优势。 AI项目与工具 2025年06月12日 23 点赞 0 评论 660 浏览
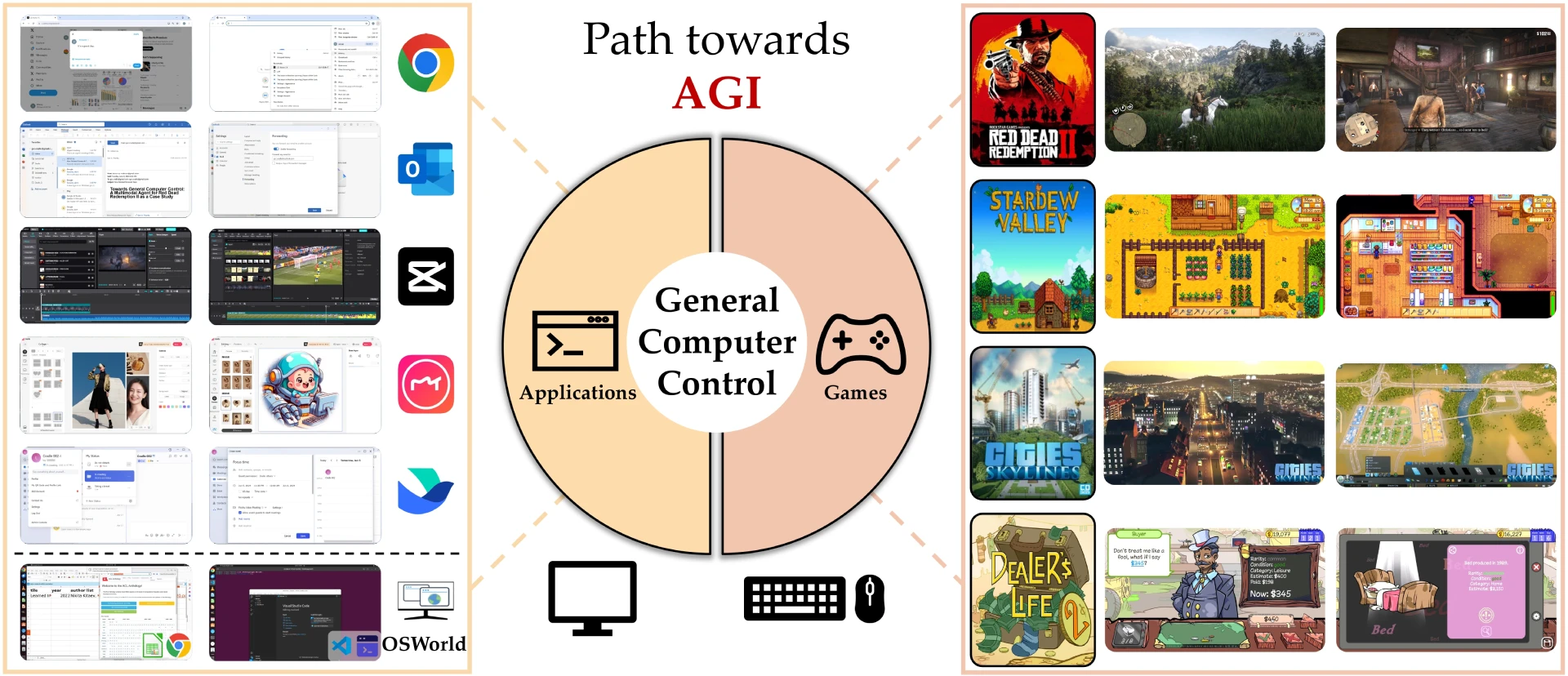
Cradle 一个通用计算机控制的多模态AI框架,它可以使AI Agent能够像人类一样,能够直接控制键盘和鼠标,实现与任意开源代码或闭源代码软件的交互。 Ai开源项目 2025年06月05日 46 点赞 0 评论 661 浏览