Globavoc海外消费者洞察 GlobaVoc是一款面向全球VoC(Voice of Customer,即客户声音)市场的AI SaaS产品,专注于从消费者评论中挖掘产品机会,尤其适合关注用户体验的品牌出海商家。 创作工具 2026年07月28日 0 点赞 0 评论 774 浏览
OpenEvidence OpenEvidence 是一款基于AI的医学知识辅助平台,通过多模型集成架构提供精准的临床问题解答、症状分析、治疗建议及医学知识更新。平台数据来源权威,确保信息准确性与可靠性,适用于临床诊断支持、治疗方案制定、医学学习和医疗文书处理等多种场景,旨在提升医疗效率与质量。 AI项目与工具 2025年06月11日 19 点赞 0 评论 774 浏览
Orbit Orbit是由Mozilla开发的浏览器扩展工具,基于AI技术实现对网页内容的快速总结与信息提取。用户可自定义摘要长度和格式,支持多种应用场景如学术研究、商业分析、新闻阅读等。该工具注重隐私保护,无需注册即可使用,适用于Gmail、Google Docs、YouTube等平台,有效提升在线阅读和信息处理效率。 AI项目与工具 2025年06月12日 66 点赞 0 评论 775 浏览
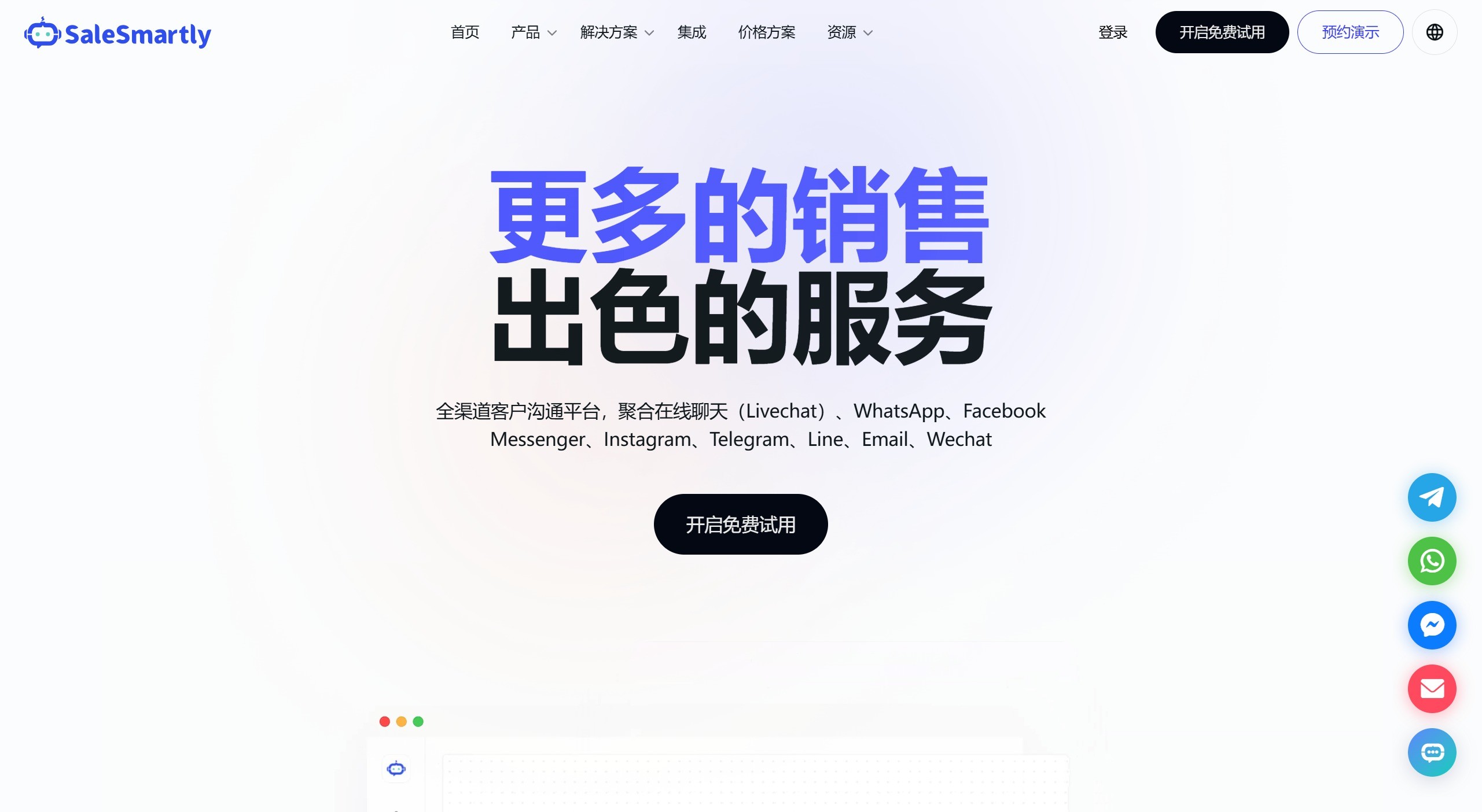
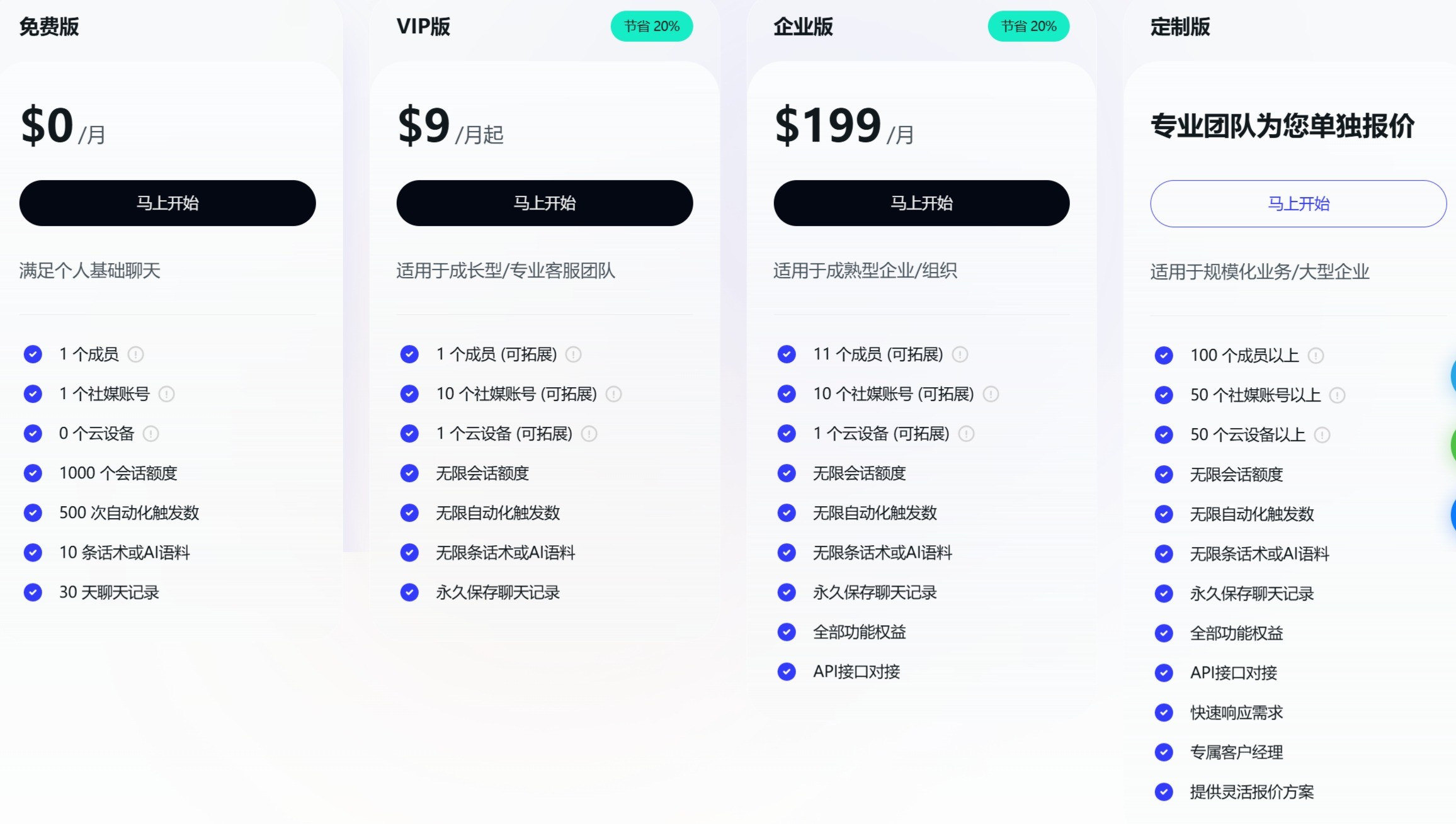
SaleSmartly 一款全渠道客户沟通平台,专注于手动客服服务,并辅以AI智能客服。它支持通过在线聊天、WhatsApp、Facebook Messenger、Instagram、Telegram、Line、Email、微信等多种方式与客户沟通。 数据分析 2025年06月05日 83 点赞 0 评论 775 浏览
Opus Clip Opus Clip是一款由Opus公司开发的AI视频剪辑工具,它能够自动从长视频中提取亮点片段,并生成短视频。该工具利用AI技术分析视频内容,识别重要时刻。Opus Clip简化了视频编辑流程,使得即使是非专业用户也能够快速制作出适合社交媒体分享的短视频。此外,它还提供了手动选择和编辑片段的功能,以及基本的视频编辑工具。 AI项目与工具 2025年06月12日 33 点赞 0 评论 775 浏览
AI新手村 AI新手村是一个由小红书与Kimi智能助手联合打造的AI技术普及平台,致力于帮助用户轻松理解并应用AI技术。该平台提供了一系列工具和指南,涵盖工作提效、技能学习、驯化AI及生活娱乐等方面,帮助用户在职场、学习和个人生活中更好地利用AI技术。无论是提高工作效率还是激发创意,AI新手村都能为用户提供实用的支持。 AI项目与工具 2025年06月12日 30 点赞 0 评论 775 浏览
Minion Agent Minion Agent 是一款基于代理框架的多功能 AI 工具,支持浏览器操作、MCP 协议、自动规划和深度研究等功能。用户可通过简单 API 快速部署,实现信息检索、数据分析等任务。其动态规划机制确保任务高效执行,同时支持多种模型和灵活配置,适用于信息研究、自动化任务、智能助手开发等多个场景。 AI项目与工具 2025年06月11日 76 点赞 0 评论 776 浏览
Chatlog Chatlog 是一款开源聊天记录分析工具,支持微信、QQ、Telegram 等平台的数据解析与可视化。通过智能分析高频词、情感倾向及活跃时段,帮助用户快速提取关键信息。具备本地化处理、数据可视化、自动化报告生成等功能,适用于个人社交分析、团队协作优化及商业客户洞察场景。 AI项目与工具 2025年05月16日 63 点赞 0 评论 776 浏览
KaloData TikTok数据分析平台,KaloData提供多种数据服务,包括TikTok爆品挖掘、达人建联、直播录屏录像、竞品店铺追踪、广告投流分析、短视频脚本导出及AI在线改写视频脚本等。 数据分析 2025年06月05日 49 点赞 0 评论 777 浏览
bossjob BossJob 是一款基于人工智能技术的全球化招聘平台,提供 AI 翻译和简历分析功能,助力跨国招聘和简历筛选。其核心功能包括多语言翻译、精准简历评估以及文化与技能匹配分析,帮助企业高效选拔优秀人才,同时为求职者提供职业发展建议。平台还计划扩展至 AI 模拟面试等功能,进一步优化招聘流程。 AI项目与工具 2025年06月12日 11 点赞 0 评论 777 浏览